 加载中…
加载中…学界 | 让机器耳濡目染:MIT提出跨模态机器学习模型
标签:
财经时评 |
分类: 公司、行业研究 |
学界 | 让机器耳濡目染:MIT提出跨模态机器学习模型
选自arXiv
机器之心编译
作者:Yusuf Aytar等人
参与:李泽南
不变性表示(invariant representation)是视觉、听觉和语言模型的核心,它们是数据的抽象结果。人们一直希望在视觉、有噪音的音频、有同义词的自然语言中获取观点和大量不变性表示。具有识别能力的不变性表示可以让机器从大量数据中学习特征,从而获得近似于人类的识别效果。但在机器学习领域,目前这一方面的研究进展有限。
对此,麻省理工学院(MIT)的 Yusuf Aytar 等人最近在一项研究中提出了全新的方法:研究人员通过多种关联信息的输入让机器学习了跨模态数据的通用表达方式。在文字语句「她跳入了泳池」中,同样的概念不仅出现在视觉上,也出现在了听觉上,如泳池的图像和水花飞溅的声音。如果这些跨模态的表示存在关联,那么它们的共同表示就具有鲁棒性。上文中的句子、泳池的图像和水声应当具有相同的内在表示。
论文:See, Hear, and Read: Deep Aligned Representations
链接:https://arxiv.org/abs/1706.00932
http://sinastorage.com/storage.caitou.sina.com.cn/products/201706/db92910568f07d757ec43470706c80b9.jpeg|
{kind=link}
摘要
我们利用大量易于获得的同步数据,让机器学习系统学会了三种主要感官(视觉、声音和语言)之间共有的深度描述。通过利用时长超过一年的视频配音和百万条配和图片匹配的句子,我们成功训练了一个深度卷积神经网络对不同信息生成共同的表示。我们的实验证明,这种表示对于一些任务是有效的,如跨模式检索或在形态之间的传递分类。此外,尽管我们的神经网络只经过了图片+文字和图片+声音的配对训练,但它也在文本和声音之间建立了联系——这在训练中未曾接触。我们的模型的可视化效果揭示了大量自动生成,用于识别概念,并独立于模态的隐藏单元。
http://sinastorage.com/storage.caitou.sina.com.cn/products/201706/3d8a8d125eedcd9c0e45c08819f31135.jpeg|
{kind=link}
图 1. 共同表示:研究人员提出了深度跨模态卷积神经网络,它可以学习三种表征方式:视觉、听觉和文字阅读。在此之上,研究人员展示了输入信息可以激活网络中的隐藏单元,其中被激发的概念位置独立于模态。
http://sinastorage.com/storage.caitou.sina.com.cn/products/201706/21d96fd22024998fc893fe5b19fd1954.jpeg|
{kind=link}
图 2. 数据集:研究人员使用了大量未加工、无约束的数据对概念表达进行训练。
http://sinastorage.com/storage.caitou.sina.com.cn/products/201706/0e089b2a0b06b42e6c97c0a525d81679.jpeg|
{kind=link}
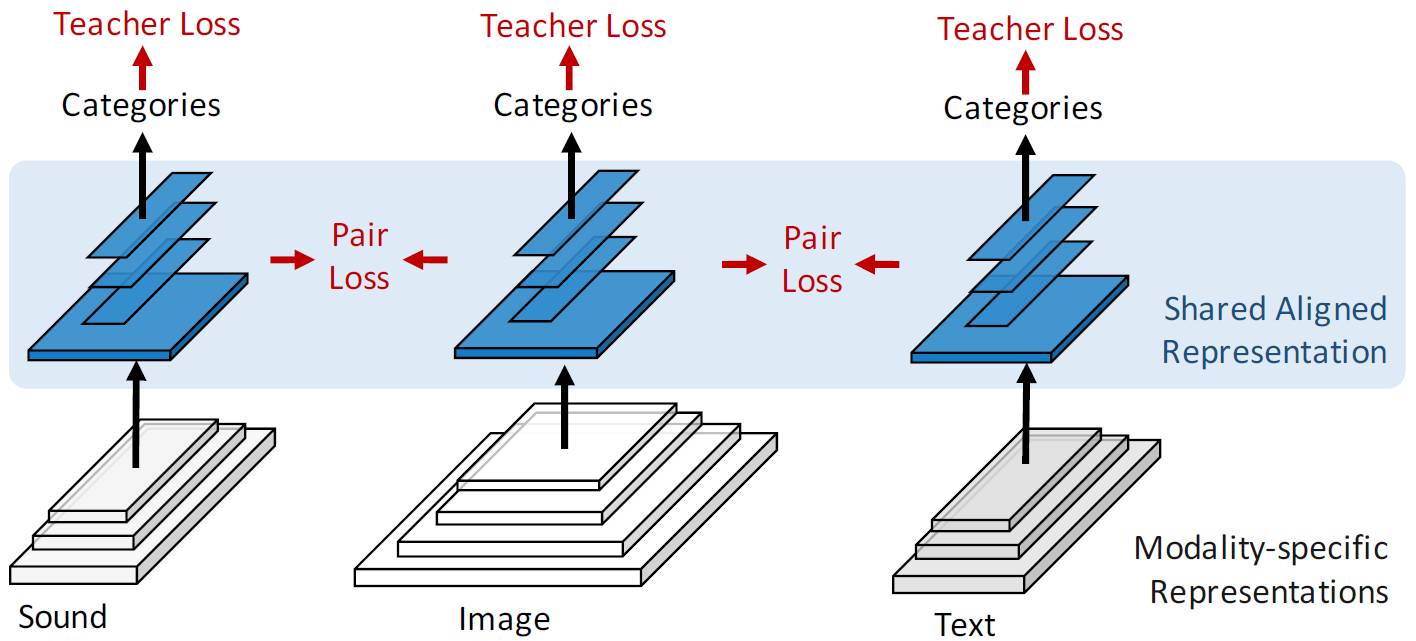
图 3. 学习通用表示方法:研究人员设计了一种能够同时接收图像、声音和文字输入的神经网络。该模型从模态专属表示(灰色)中产生一种通用表示,同时适用于不同模态(蓝色)。研究人员同时使用模型转换损失和配比排名损失来训练这个模型。模态专有层是卷积的,不同模态的共享层则是全连接的。
http://sinastorage.com/storage.caitou.sina.com.cn/products/201706/96647e054f6785a1c74f4c9737b56450.jpeg|
{kind=link}
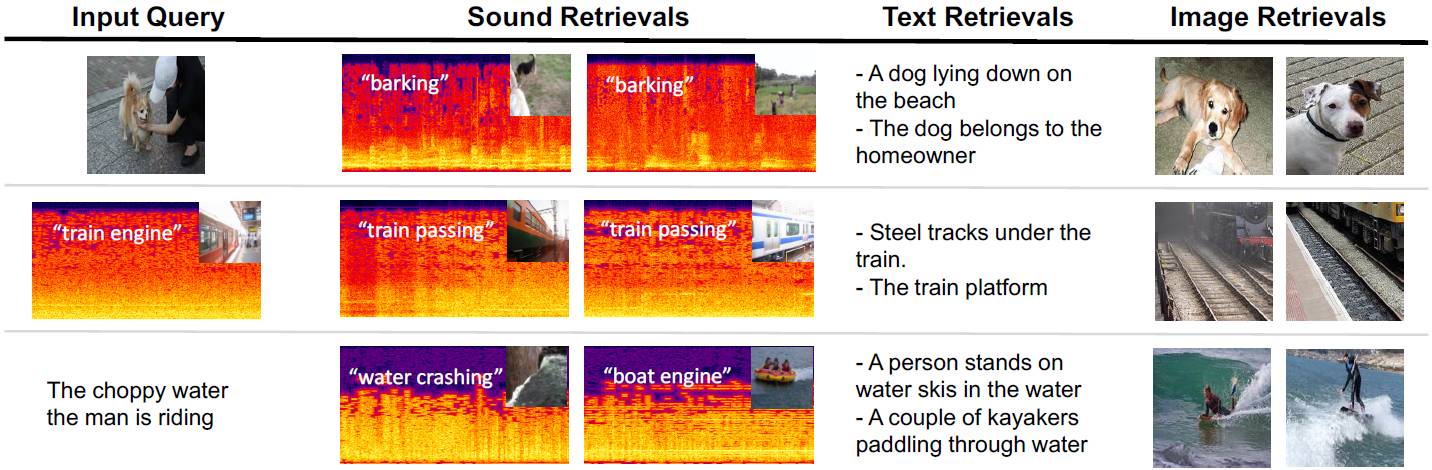
图 4. 跨模式反演示例:MIT 的研究人员展示了使用深度表示,跨声音、图像和文字三种模态的顶层反演
http://sinastorage.com/storage.caitou.sina.com.cn/products/201706/34752bedacaff34c884aa9ac5e6a0d43.jpeg|
{kind=link}
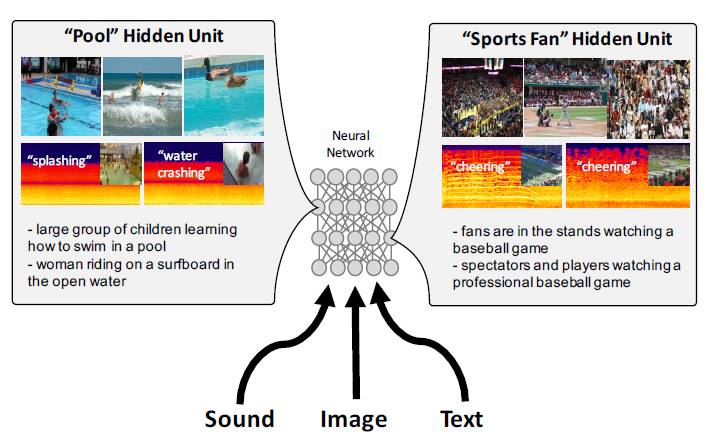
图 5. 隐藏单元的可视化:研究人员通过模型的可视化发现了一些隐藏单元。注意:频谱图(红/黄色的热区显示)之外,还有原始视频和与之对应的描述声音,后者仅用于可视化目的。
不变性表示可以让计算机视觉系统可以在不受约束的、现实世界环境中高效运行。在实验中,研究人员发现了一些联结表达方式具有更高的分类和检索性能,可以应对未遇到过的新情况。麻省理工学院的学者们相信,对于下一代机器感知而言,跨模态的表示具有重要意义。 
本文为机器之心编译,转载请联系本公众号获得授权。
![]() 喜欢
喜欢
0
![]() 赠金笔
赠金笔