 加载中…
加载中…R语言-如何处理回归中的异常值点
标签:
r语言数据分析数据分析师培训数据挖掘 |
异常观测值
一个全面的回归分析要覆盖对异常值的分析,包括离群点、高杠杆值点和强影响点。这些数据点需要更深入的研究,因为它们在一定程度上与其他观测点不同,可能对结果产生较大的负面影响。下面我们依次学习这些异常值。
8.4.1
离群点是指那些模型预测效果不佳的观测点。它们通常有很大的、或正或负的残差(Yi-Y
car包也提供了一种离群点的统计检验方法。
http://cda.pinggu.org/uploadfile/image/20170530/20170530065644_81204.png
{kind=link}
此处,你可以看到Nevada被判定为离群点(p=0.048)。注意,该函数只是根据单个最大(或正或负)残差值的显著性来判断是否有离群点。若不显著,则说明数据集中没有离群点;若显著,则你必须删除该离群点,然后再检验是否还有其他离群点存在。
8.4.2
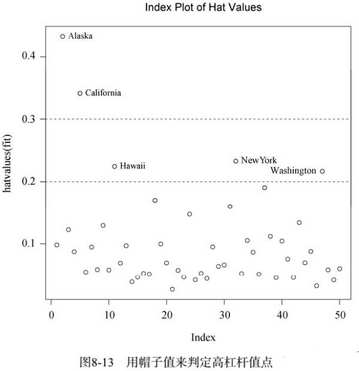
高杠杆值观测点,即是与其他预测变量有关的离群点。换句话说,它们是由许多异常的预测变量值组合起来的,与响应变量值没有关系。高杠杆值的观测点可通过帽子统计量(hat
statistic)判断。对于一个给定的数据集,帽子均值为p/n,其中p
http://cda.pinggu.org/uploadfile/image/20170530/20170530065612_50195.png
{kind=link}
结果见图8-13。
http://cda.pinggu.org/uploadfile/image/20170530/20170530065551_38673.png
{kind=link}
水平线标注的即帽子均值2倍和3倍的位置。
8.4.3
强影响点,即对模型参数估计值影响有些比例失衡的点。例如,若移除模型的一个观测点时模型会发生巨大的改变,那么你就需要检测一下数据中是否存在强影响点了。有两种方法可以检测强影响点:
http://cda.pinggu.org/uploadfile/image/20170530/20170530065524_30301.png
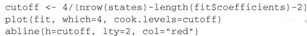{kind=link}
通过图形可以判断Alaska、
http://cda.pinggu.org/uploadfile/image/20170530/20170530065502_19041.png
{kind=link}
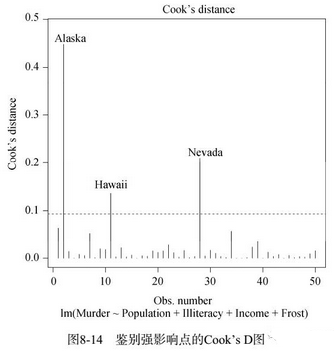
结果如图8-15所示。
http://cda.pinggu.org/uploadfile/image/20170530/20170530065437_93602.png
{kind=link}
图形一次生成一个,用户可以通过单击点来判断强影响点。按下Esc,或从图形菜单中选择Stop,或右击,便可移动到下一个图形。我已在左下图中鉴别出Alaska为强影响点。
图中的直线表示相应预测变量的实际回归系数。你可以想象删除某些强影响点后直线的改变,以此来估计它的影响效果。例如,来看左下角的图(“
http://cda.pinggu.org/uploadfile/image/20170530/20170530065416_95765.png
{kind=link}
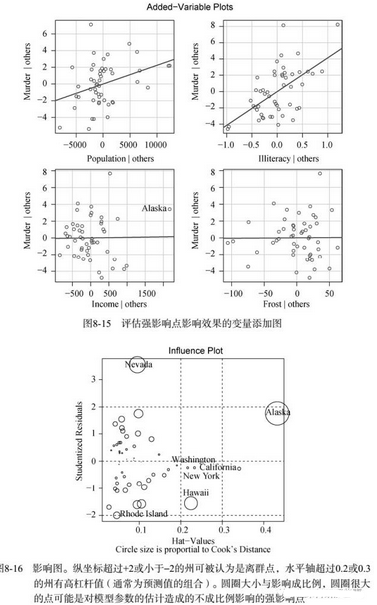
图8-16反映出Nevada和Rhode
Island是离群点,
http://cda.pinggu.org/uploadfile/image/20170530/20170530065350_52993.png
{kind=link}
![]() 喜欢
喜欢
0
![]() 赠金笔
赠金笔