 加载中…加载中…
加载中…加载中…
标签:
教育 |
2011-10-02
08:58:28|
Using STATA 11:
Define the x and y matrices.
: b=invsym(x’x)
标签:
it |
描述统计
describe
describe命令可以描述数据文件的整体,包括观测总数,变量总数,生成日期,每个变量的存储类型(storage
type),标签(label)等。
list [varlist] [if exp] [in range]
summarize [varlist] [weight] [if exp] [in range] [,detail]
summarize可以提供varlist指定变量(可以不止一个)的如下统计量:Percentiles(分位数),四大最大的数和四个最小的数,Variance(方差),Std.
Dev.(标准差),Skewness(偏度),Kurtosis(斜度)
tabstat
tabstat varlist [weight] [if exp] [in range] [, stats(statname
[...]) ]
tabstat提供[, stats(statname [...])
]指定的统计量,可供选择的有mean(均值),count(非缺失观测值个数),sum(总和),max(最大值),min(最小值),range(最大值-最小值),sd(标准差),var(方差),cv(变易系数=标准差/均值),skewness(偏度),kurtosis(斜度),median(中位数),p1(1%分位数,类似地有p5,
p10, p25,
标签:
杂谈 |
|
||
标签:
教育 |
表 我国1978-2002年全社会客运量及预测值 单位:万人
| 年份 | 时间t | 全社会客运量y | 各期的一次指数平滑值http://wiki.mbalib.com/w/images/math/5/c/2/5c2f495ad0869994a3e7dcaf |
各期的二次指数平滑值http://wiki.mbalib.com/w/images/math/3/1/a/31a3aac99dd5668600b6a1f9 |
at |
|---|
标签:
it |
MATLAB画时间序列的自相关函数和偏自相关函数图
标签:
教育 |
控制变量在工具书中的解释:除自变量之外,一切能使因变量发生变化的变量。这类变量是应该加以控制的,如果不加控制,它也会造成因变量的变化,即自变量和一些未加控制的因素共同造成了因变量的变化,这叫自变量的混淆。因此,只有将自变量以外一切能引起因变量变化的变量控制好,才能弄清实验中的因果关系。
控制变量——在实验中,不仅仅只有自变量才是和因变量有关的,于自变量之外往往存在额外相关变量,此类变量简称额外变量,因其必须被想办法控制,在实验中保持恒定不变,又称其为控制变量。
标签:
教育 |
注:JB统计量对应的p大于0.05,则表明非正态,这点跟sktest和swilk检验刚好相反;
dta为数据文件;
gph为图文件;
do为程序文件;
注意stata要区别大小写;
不得用作用户变量名:
_all _n _N _skip _b _coef _cons _pi _pred _rc _weight double
float long int in if using with
命令:
读入数据一种方式
input
1
2
3
4
5
end
su/summarise/sum x 或 su/summarise/sum x,d
对分组的描述:
sort group
by group:su x
%%%%%
tabstat economy,stats(max)
%%stats括号里可以是:mean,count(非缺失观测值个数),sum(总和),max,min,range,
%%
标签:
it |
原文地址:http://yinlianqian.blog.163.com/blog/static/6488756720082268510559/
作者:思想的成长轨迹
写在这里保存下来,我自己以后要看看:)
1. 点选 图示,进入WinBugs,开启 (1)新的程式编辑视窗or (2)已存在的程式功能表列:File-New 功能表列:File-Open
2. 撰写程式:程式包含三部份.
(1) Model:建构贝氏统计模式,设定各参数的prior distribution及各参数间的关系等.
(2) Data:以list指令起始,列出各参数的样本观察值及样本个数(N= ).
(3) Initial value:同样运用list指令,列出各参数的起始值.
ps:上述三大
标签:
it |

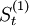{kind=link}
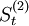{kind=link}