 加载中…
加载中…淘宝(大数据库应用)
标签:
it |
第一部分、mapreduce模式与hadoop框架深入浅出
架构扼要
- Mapreduce是一种模式。
- Hadoop是一种框架。
- Hadoop是一个实现了mapreduce模式的开源的分布式并行编程框架。
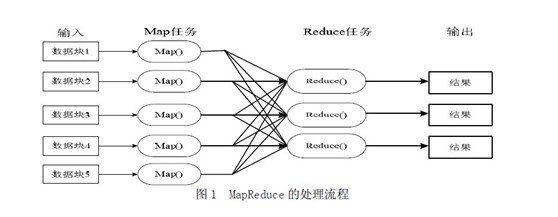
Mapreduce模式
http://hi.csdn.net/attachment/201108/20/0_1313816520nlst.gif
{kind=link}
http://hi.csdn.net/attachment/201108/20/0_1313816570mW63.gif
{kind=link}
http://hi.csdn.net/attachment/201108/20/0_1313816620g8Ru.gif
{kind=link}
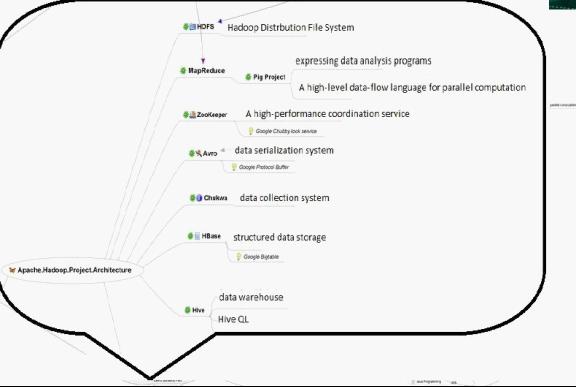
Hadoop框架
http://hi.csdn.net/attachment/201108/20/0_1313816645ZfTU.gif
{kind=link}
Hadoop的组成部分
我们已经知道,Hadoop是Google的MapReduce一个Java实现。MapReduce是一种简化的分布式编程模式,让程序自动分布到一个由普通机器组成的超大集群上并发执行。Hadoop主要由HDFS、MapReduce和HBase等组成。具体的hadoop的组成如下图: http://hi.csdn.net/attachment/201108/20/0_131381852997kj.gif
{kind=link}
http://hi.csdn.net/attachment/201108/20/0_1313816699CJaQ.gif
{kind=link}
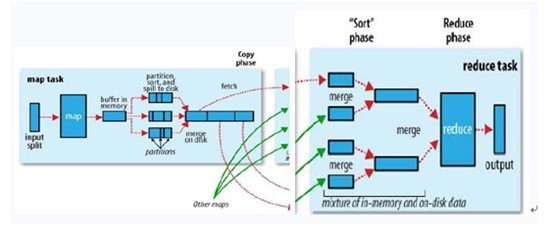
一个MapReduce作业(job)通常会把输入的数据集切分为若干独立的数据块,由 Map任务(task)以完全并行的方式处理它们。框架会对Map的输出先进行排序,然后把结果输入给Reduce任务。通常作业的输入和输出都会被存储在文件系统中。整个框架负责任务的调度和监控,以及重新执行已经失败的任务。如下图所示(Hadoop MapReduce处理流程图): http://hi.csdn.net/attachment/201108/20/0_1313816714BlYw.gif
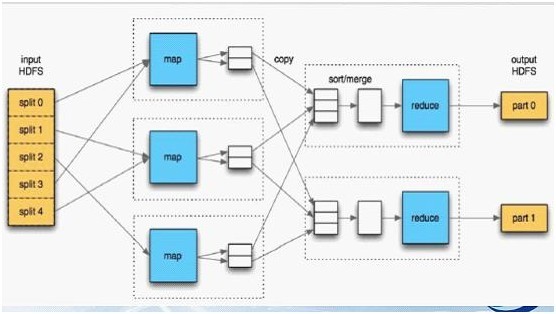{kind=link}
主要特点:
存储方式是将结构化的数据文件映射为一张数据库表。提供类SQL语言,实现完整的SQL查询功能。可以将SQL语句转换为MapReduce任务运行,十分适合数据仓库的统计分析。
不足之处:
采用行存储的方式(SequenceFile)来存储和读取数据。效率低:当要读取数据表某一列数据时需要先取出所有数据然后再提取出某一列的数据,效率很低。同时,它还占用较多的磁盘空间。
由于以上的不足,有人(查礼博士)介绍了一种将分布式数据处理系统中以记录为单位的存储结构变为以列为单位的存储结构,进而减少磁盘访问数量,提高查询处理性能。这样,由于相同属性值具有相同数据类型和相近的数据特性,以属性值为单位进行压缩存储的压缩比更高,能节省更多的存储空间。如下图所示(行列存储的比较图):
http://hi.csdn.net/attachment/201108/20/0_1313816776mUUH.gif
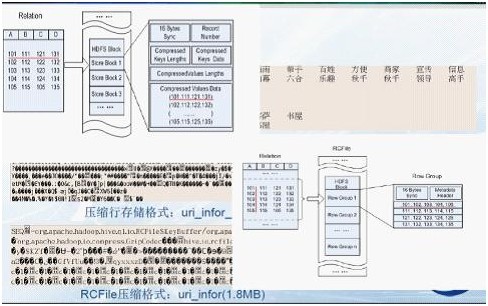{kind=link}
4、
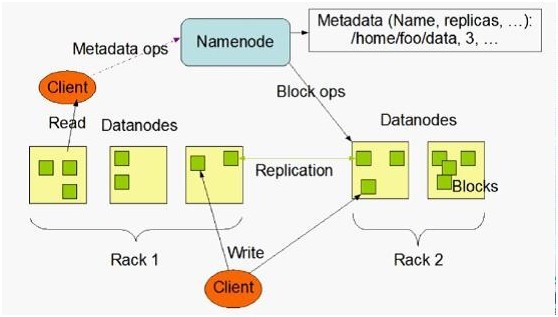
HBase是一个分布式的、面向列的开源数据库,它不同于一般的关系数据库,是一个适合于非结构化数据存储的数据库。另一个不同的是HBase基于列的而不是基于行的模式。HBase使用和 BigTable非常相同的数据模型。用户存储数据行在一个表里。一个数据行拥有一个可选择的键和任意数量的列,一个或多个列组成一个ColumnFamily,一个Fmaily下的列位于一个HFile中,易于缓存数据。表是疏松的存储的,因此用户可以给行定义各种不同的列。在HBase中数据按主键排序,同时表按主键划分为多个HRegion,如下图所示(HBase数据表结构图): http://hi.csdn.net/attachment/201108/20/0_131381682603ZU.gif
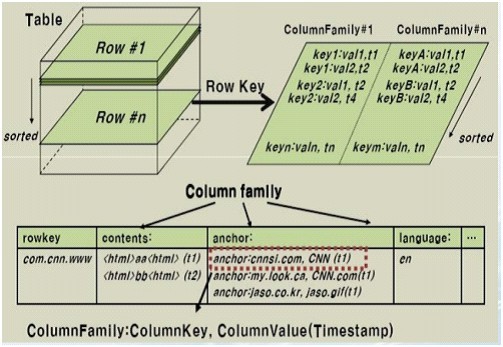{kind=link}
http://hi.csdn.net/attachment/201108/20/0_1313816841DQQI.gif
第二部分、淘宝海量数据产品技术架构解读—学习海量数据处理经验
{kind=link}
淘宝海量数据产品技术架构
http://hi.csdn.net/attachment/201108/20/0_1313816866b9b9.gif
图2-1 淘宝海量数据产品技术架构
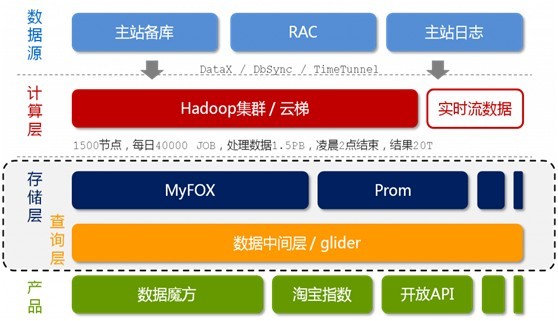{kind=link}
- 数据来源层。存放着淘宝各店的交易数据。在数据源层产生的数据,通过DataX,DbSync和Timetunel准实时的传输到下面第2点所述的“云梯”。
- 计算层。在这个计算层内,淘宝采用的是hadoop集群,这个集群,我们暂且称之为云梯,是计算层的主要组成部分。在云梯上,系统每天会对数据产品进行不同的mapreduce计算。
- 存储层。在这一层,淘宝采用了两个东西,一个使MyFox,一个是Prom。MyFox是基于MySQL的分布式关系型数据库的集群,Prom是基于hadoop Hbase技术 的(读者可别忘了,在上文第一部分中,咱们介绍到了这个hadoop的组成部分之一,Hbase—在hadoop之内的一个分布式的开源数据库)的一个NoSQL的存储集群。
- 查询层。在这一层中,有一个叫做glider的东西,这个glider是以HTTP协议对外提供restful方式的接口。数据产品通过一个唯一的URL来获取到它想要的数据。同时,数据查询即是通过MyFox来查询的。下文将具体介绍MyFox的数据查询过程。
-
产品层。简单理解,不作过多介绍。
MyFOX
如下图所示,是MySQL的数据查询过程:
http://hi.csdn.net/attachment/201108/20/0_1313816897fTJ3.gif
{kind=link}
在MyFOX的每一个节点中,存放着热节点和冷节点两种节点数据。顾名思义,热节点存放着最新的,被访问频率较高的数据;冷节点,存放着相对而来比较旧的,访问频率比较低的数据。而为了存储这两种节点数据,出于硬件条件和存储成本的考虑,你当然会考虑选择两种不同的硬盘,来存储这两种访问频率不同的节点数据。如下图所示: http://hi.csdn.net/attachment/201108/20/0_131381690985qz.gif
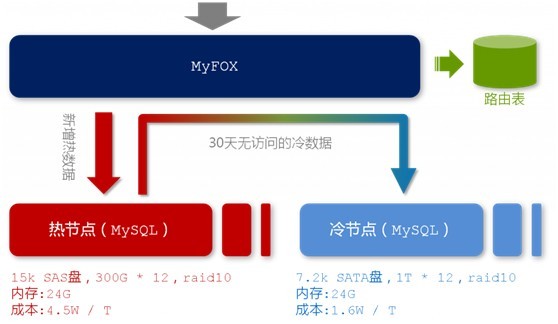{kind=link}
Prom
出于文章篇幅的考虑,本文接下来不再过多阐述这个Prom了。如下面两幅图所示,他们分别表示的是Prom的存储结构以及Prom查询过程:
http://hi.csdn.net/attachment/201108/20/0_131381694575YP.gif
图2-4 Prom的存储结构
http://hi.csdn.net/attachment/201108/20/0_13138169589vHu.gif
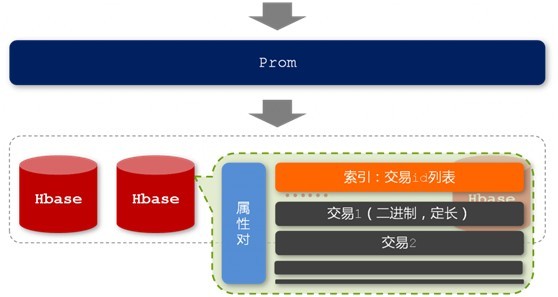{kind=link}
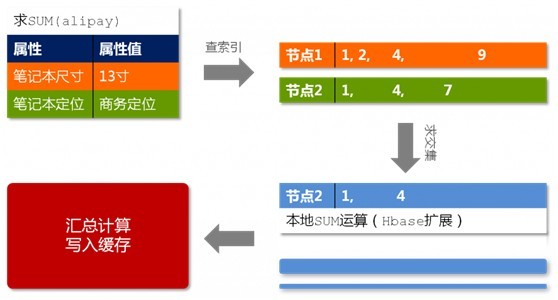{kind=link}
glide的技术架构
http://hi.csdn.net/attachment/201108/20/0_1313816987Nd2a.gif
图2-6 glider的技术架构
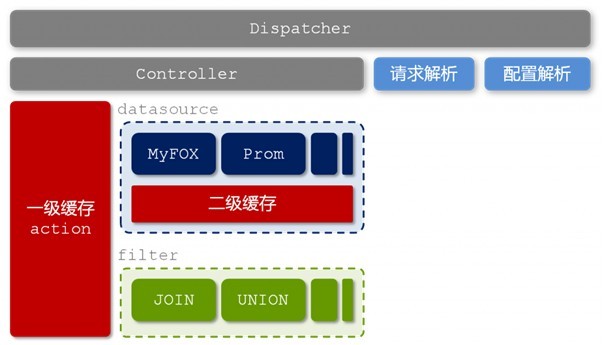{kind=link}
缓存
在上文图2-6中我们看到,glider中存在两层缓存,分别是基于各个异构“表”(datasource)的二级缓存和整合之后基于独立请求的一级缓存。除此之外,各个异构“表”内部可能还存在自己的缓存机制。
http://hi.csdn.net/attachment/201108/20/0_1313817000lHd5.gif
图2-7 缓存控制体系
{kind=link}
-
缓存穿透是指查询一个一定不存在的数据,由于缓存是不命中时被动写的,并且出于容错考虑,如果从存储层查不到数据则不写入缓存,这将导致这个不存在的数据每次请求都要到存储层去查询,失去了缓存的意义。至于如何有效地解决缓存穿透问题,最常见的则是采用布隆过滤器(这个东西,在我的此篇文章中有介绍:),将所有可能存在的数据哈希到一个足够大的bitmap中,一个一定不存在的数据会被这个bitmap拦截掉,从而避免了对底层存储系统的查询压力。
本文参考:
-
基于云计算的海量数据存储模型,侯建等。
-
基于hadoop的海量日志数据处理,王小森
-
基于hadoop的大规模数据处理系统,王丽兵。
-
淘宝数据魔方技术架构解析,朋春。
-
Hadoop作业调优参数整理及原理,guili。
读者点评@xdylxdyl:
-
We want to count all the books in the library. You count up shelf #1, I count up shelf #2. That's map. The more people we get, the faster it goes. Now we get together and add our individual counts. That's reduce。
-
数据魔方里的缓存穿透,架构,空数据缓存这些和Hadoop一点关系都么有,如果是想讲一个Hadoop的具体应用的话,数据魔方这部分其实没讲清楚的。
-
感觉你是把两个东西混在一起了。不过这两个都是挺有价值的东西,或者说数据魔方的架构比Hadoop可能更重要一些,基本上大的互联网公司都会选择这么做。Null对象的缓存保留五分钟未必会有好的结果吧,如果Null对象不是特别大,数据的更新和插入不多也可以考虑实时维护。
-
Hadoop本身很笨重,不知道在数据魔方里是否是在扮演着实时数据处理的角色?还是只是在做线下的数据分析的?
结语:写文章是一种学习的过程。尊重他人劳动成果,转载请注明出处。谢谢。July、2011/8/20。完。
![]() 喜欢
喜欢
0
![]() 赠金笔
赠金笔