 加载中…
加载中…“数据会说谎”的真实例子有哪些?
标签:
股票 |
“数据会说谎”的真实例子有哪些?
文/谢科(知乎)
本文系作者授权“清南”发布,如要转载请与作者本人联系。
截图说话——哗众取宠的美国Fox news经常用的一些招数。
这些招数更多的是从视觉上给人一种“错觉”。比如说,本来不大的差异,截掉Y轴的一部分,瞬间差异就会让看的人觉得——差得这么多!!!
想象你明天要跟你的经理作报告,手里有一堆结果,但是显然这些结果对于之前的方法只有边际的增长——好消息是,你几乎一定可以找到一个方法,在数据变化不大的时候却给人造成视觉的冲击。
例子:
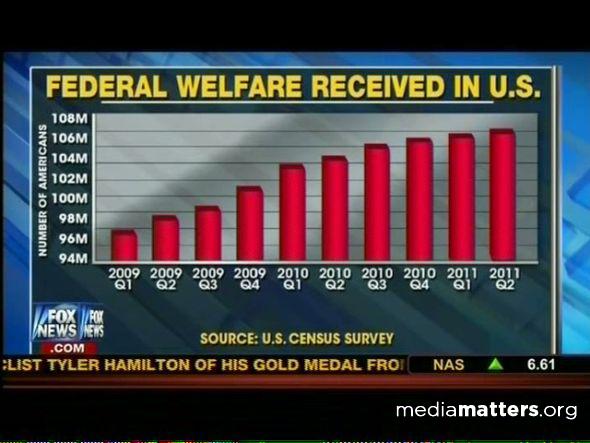
1)在趋势图中,为了说明增长趋势多明显,把Y调成不从0开始。这样差距会看起来很大,增长很大,但是如果把Y轴从0开始看的话,会显得基本没有差距。
http://pic2.zhimg.com/804a3f61cd10160443636cf5b1033961_b.jpg差距够大吧!!!巨量增长啊!我们公司的财务情况这样的话,公司明年就得IPO啊!!
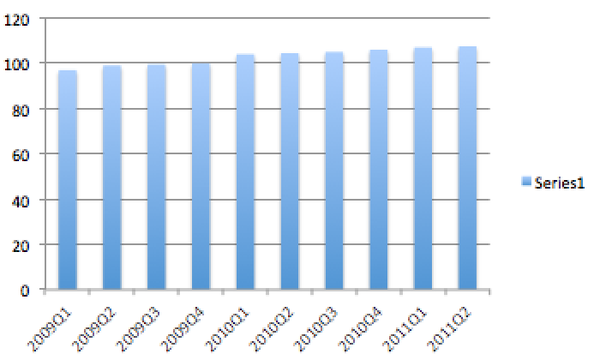
可惜Y从0开始的话,这图应该看起来的样子是:
http://pic3.zhimg.com/69fdd79bca903ec0cc63db2431672a62_b.jpgp.s.刚发现在用Excel画这图的时候,excel都自动把Y轴的起始值调成比最小值多一点!这样看起来差距真是巨明显有没有!看来M$真是很懂画图的真正需求啊:D
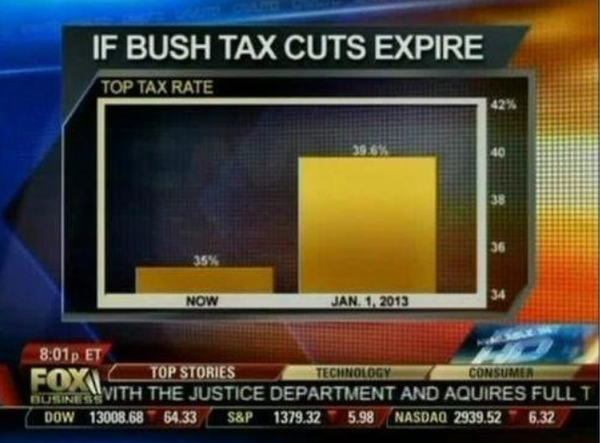
2) 另外一个例子,作两两比较的时候把Y的值从高位开始,造成俩差距巨大的错觉
http://pic2.zhimg.com/abce2a42e8fbcd551b0f90b00692c261_b.jpg看啊,右边比左边高了4倍不止!!!咦,等等,不是就39.6%跟35%的差别吗....这...
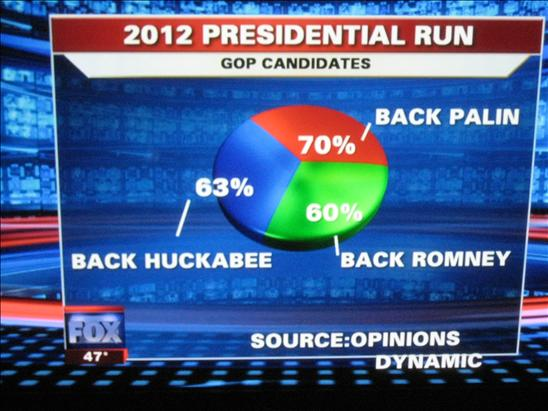
3) 分数加起来不等于一,放大差距。
http://pic3.zhimg.com/a300f5f64e7f9b2a7e8616e213d91ab2_b.jpg图上的数据normalize一下的话那么佩林是36.2%,32.6%,31.0%,直观差距不大。但是在这个饼型图里瞬间变成了10%的差距!这个比较明显的话那看下面
这里
http://pic1.zhimg.com/e8ca19409759b0f6d5cd76db1b020f58_b.jpg一扫的话没发现这里百分数加起来不等于1了吧。
4) 挑取x轴的数据以捏造趋势
http://pic2.zhimg.com/02839064fc6b4197a6fcffa3c15c6b0d_b.jpg
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
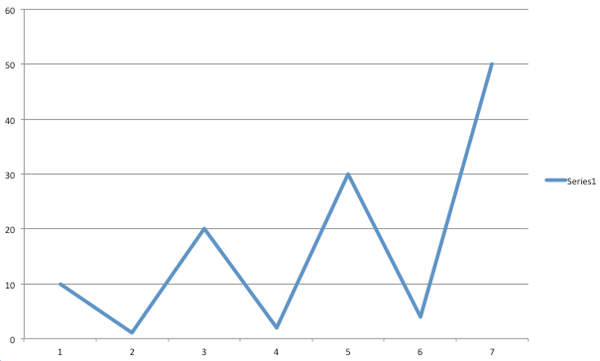
假设数据的波动性很大,比如说如下
10, 1, 20, 3, 30, 4, 50
看起来应该是
http://pic1.zhimg.com/261400d3ccf4f5b262bec500681179d4_b.jpg擦勒,公司的财务状况这么不稳定!!!怎么办!
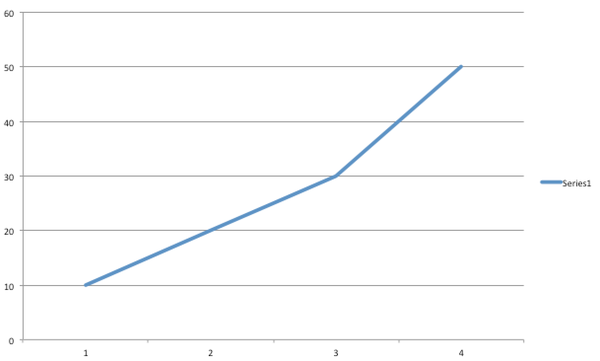
没关系——如果我只抽取奇数项的话(挑取x轴,虽然挑得好像是很有系统地——奇数,但是你总能想到一个看着挑得系统的方法)
就会看着像
http://pic1.zhimg.com/632537beed54170fb849db4b85f8f2a4_b.jpgTMD明年又可以上市了。。。
{kind=link}
{kind=link}
等等等等...
部分图片来源于:simplystats
来源邀稿:谢科
原文链接:
http://www.zhihu.com/question/19578400/answer/24843398
http://www.changweibo.com/ueditor/php/upload/20150420/142951367745.jpg
{kind=link}
http://www.zhihu.com/question/19578400/answer/24843398
![]() 喜欢
喜欢
0
![]() 赠金笔
赠金笔