 加载中…
加载中…压测基本概念
标签:
jemeter |
分类: jmeter |
性能测试类型
基准测试:在给系统施加较低压力时,查看系统的运行状况并记录相关数做为基础参考
负载测试:是指对系统不断地增加压力或增加一定压力下的持续时间,直到系统的某项或多项性能指标达到安全临界值,例如某种资源已经达到饱和状态等
。
压力测试:压力测试是评估系统处于或超过预期负载时系统的运行情况,关注点在于系统在峰值负载或超出最大载荷情况下的处理能力。
稳定性测试:在给系统加载一定业务压力的情况下,使系统运行一段时间,以此检测系统是否稳定。
并发测试:测试多个用户同时访问同一个应用、同一个模块或者数据记录时是否存在死锁或者其他性能问题
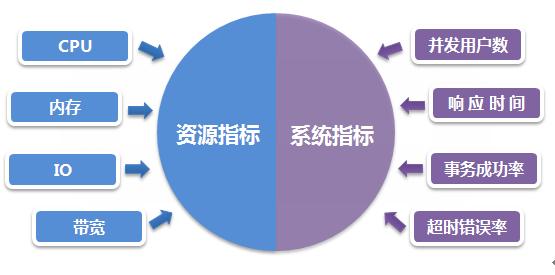
软件性能测试是执行、监控—〉分析—〉调优 不断优化的过程,其中监控数据是主要部分,监控数据主要包括资源指标和系统指标两个部分,如下:
http://www.uml.org.cn/Test/images/2014081821.jpg
{kind=link}
性能测试系统指标基本概念
1、响应时间
定义:从用户发送一个请求到用户接收到服务器返回的响应数据这段时间就是响应时间
关键路径:下图为一次http请求经过的路径,请求会经过网络发送到web服务器进行处理,如果需要操作DB,再由网络转发到数据库进行处理,然后返回值给web服务器,web服务器最后把结果数据通过网络返回给客户端

计算方法:Response
time = (N1+N2+N3+N4)+ (A1+A2+a3),即:(网络时间 + 应用程序处理时间)
响应时间-负载对应关系:
图中拐点说明:
(1)响应时间突然增加
(2)意味着系统的一种或多种资源利用达到的极限
(3)通常可以利用拐点来进行性能测试分析与定位
2、吞吐量/QPS/TPS
吞吐量:
定义:单位时间内系统处理的客户端请求的数量
计算单位:一般使用请求数/秒做为吞吐量的单位,也可以使用页面数/秒表表示。
另外,从业务角度来说也可以使用 访问人数 /天 或 页面访问量/天 做为单位。
计算方法:Throughput = (number of requests) / (total time).
吞吐量-负载对应关系:
图中拐点说明:
(1)吞吐量逐渐达到饱和
(2)意味着系统的一种或多种资源利用达到的极限
(3)通常可以利用拐点来进行性能测试分析与定位
QPS:Queries Per Second,意思是“每秒查询率”,是一台服务器每秒能够响应的查询次数,是对一个特定的查询服务器(比如是读写分离的架构,就是读的服务器)在规定时间内所处理流量多少的衡量标准。
TPS:TransactionsPerSecond,意思是每秒事务数,一个事务是指一个客户机向服务器发送请求然后服务器做出反应的过程。客户机在发送请求时开始计时,收到服务器响应后结束计时,以此来计算使用的时间和完成的事务个数。
qps,如果是对一个页面请求一次,形成一个tps,但一次页面请求,可能产生多次对服务器的请求(页面上有很多html资源,比如图片等),服务器对这些请求,就可计入“Qps”之中;
3、并发数:
(1)并发用户数:某一物理时刻同时向系统提交请求的用户数,提交的请求可能是同一个场景或功能,也可以是不同场景或功能。
(2)在线用户数:某段时间内访问系统的用户数,这些用户并不一定同时向系统提交请求
(3)系统用户数:系统注册的总用户数据
三者之间的关系:系统用户数 >= 在线用户数 >= 并发用户数
4、资源指标
定义:指的是对不同系统资源的使用程度,通常以占用最大值的百分比来衡量
通常需要关注的服务器资源如下:
(1)CPU:就像人的大脑,主要负责相关事情的判断以及实际处理的机制,长时间情况下,一般可接受上限不超过85%。
一般情况下CPU满负荷工作,有时候并不能判定为CPU出现瓶颈,比如Linux总是试图要CPU尽可能的繁忙,使得任务的吞吐量最大化,即CPU尽可能最大化使用。因此,一般判断CPU 为瓶颈,主要从两方面:
一是CPU空闲持续为0,
二是运行队列大于CPU核数(经验值3-4倍),即可判定存在瓶颈,对于CPU高消耗主要由什么引起的,可能是应用程序不合理造成,也可能是硬件资源不足,需要具体问题具体分析,比如问题SQL语句引起,则需要跟踪并优化引起CPU使用过高的SQL语句。
(2)内存:大脑中的记忆块区,将眼睛,皮肤等收集到的信息记录起来的地方,以供cpu进行判断,但是是临时的,访问速度快,如果关机或断电这里的数据会消失。内存利用率=(1-空闲内存/总内存大小)*100%;
判断内存是否是瓶颈的方法:一般至少有10%可用内存,内存使用率可接受上限为85%。当空闲内存变小时,系统开始频繁地调动磁盘页面文件,空闲内存过小可能是内存不足或内存泄漏引起,需要根据系统实际情况监控分析。
(3)磁盘IO:大脑中的记忆区块,将重要的数据保存起来(永久保存,关机或断电不会丢失,速度慢),以便将来再次使用这些数据。
计算每磁盘I/O数
每磁盘I/O数可用来与磁盘的I/O能力进行对比,如果经过计算得到的每磁盘I/O数超过了磁盘标称的I/O能力,则说明确实存在磁盘的性能瓶颈,每磁盘I/O计算方法如下表:
http://www.uml.org.cn/Test/images/2014081828.png
{kind=link}
监控磁盘读写,如果磁盘长时间进行大数据量读写操作,且cpu等待超过20%,则说明磁盘I/O存在问题,考虑提高磁盘I/O读写性能。
(4)网络带宽:一般使用计数器Bytes Total/sec来度量,Bytes
Total/sec表示为发送和接收字节的速率,包括帧字符在内。判断网络连接速度是否是瓶颈,可以用该计数器的值和目前网络的带宽比较;
判断网络带宽是否是瓶颈的方法:判断网络带宽是否是系统运行性能瓶颈的首要条件是网络带宽是否会影响系统交易执行性能。
例如:减小网络带宽,并发用户数、响应时间与事务通过率等性能指标是否不能接受;或者增加网络带宽,并发用户数、响应时间与事务通过率等性能指标会得到明显提高;
在实际性能测试中,如果发现始终报连接超时,而实际手工访问可以正常访问,可以通过ping应用服务器IP或网关IP,如果出现网络严重延迟或丢包,则说明网络不稳定,需要检查网络。
(5)平均负载,上一分钟同时处于“就绪”状态的平均进程数。Load这个东西怎么理解呢,就像一条马路,有N个车道,如果N个进程进入车道,那么正好一人一个,再多一辆车就占不到车道,要等有一个车空出车道。
在CPU中可以理解为CPU可以并行处理的任务数,那么就是“CPU个数 * 核数”;
如果CPU Load = CPU个数 * 核数 那么就是说CPU正好满负载,再多一点,可能就要出问题了,有任务不能被及时分配处理器,那么保证性能的话,最好是小于CPU个数 * 核数 *0.7。
Load Average是
CPU的 Load,它所包含的信息是在一段时间内 CPU正在处理以及等待 CPU处理的进程数之和的统计信息,也就是
CPU使用队列的长度的统计信息。Load Average 的值应该小于“CPU个数 * 核数 *0.7 ”
,否则就高了。
比如:
1个1核CPU,Load
1个4核的CPU,Load
资源利用-负载对应关系:
图中拐点说明:
(1)服务器某荐资源使用逐渐达到饱和
(2)通常可以利用拐点来进行性能测试分析与定位
通过对资源指标四个指标的分析,实际上各个方面都是互相依赖的,不能孤立的单从某个方面进行排查。当一个方面出现性能问题时,往往会引发其他方面的性能问题,例如,大量的磁盘读写势必消耗CPU和IO资源,而内存的不足会导致频繁地进行内存页写入磁盘、磁盘写到内存的操作,造成磁盘IO瓶颈,同时,大量的网络流量也会造成CPU过载,所以,在分析性能问题时,需要从各个方面进行考虑。
其它常用概念:
TPS:Transactions Per
Second,每秒事务数
思考时间:用户每个操作后的暂停时间,或者叫操作之间的间隔时间,此时间内是不对服务器产生压力的
点击数:每秒钟用户向WEB服务器提交的HTTP请求数。
这个指标是WEB应用特有的一个指标:WEB应用是”请求-响应”模式,用户发出一次申请,服务器就要处理一次,所以点击是WEB应用能够处理的交易的最小单位。如果把每次点击定义为一个交易,点击率和TPS就是一个概念。容易看出,点击率越大,对服务器的压力越大。点击率只是一个性能参考指标,重要的是分析点击时产生的影响。需要注意的是,这里的点击并非指鼠标的一次单击操作,因为在一次单击操作中,客户端可能向服务器发出多个HTTP请求.
PV:访问一个URL,产生一个PV(Page View,页面访问量),每日每个网站的总PV量是形容一个
网站规模的重要指标。
UV:作为一个独立的用户,访问站点的所有页面均算作一个UV(Unique Visitor,用户访问)
性能测试模型
曲线拐点模型
X轴代表并发用户数,Y轴代表资源利用率、吞吐量、响应时间。X轴与Y轴区域从左往右分别是轻压力区、重压力区、拐点区。
随着并发用户数的增加,在轻压力区的响应时间变化不大,比较平缓,进入重压力区后呈现增长的趋势,最后
进入拐点区后倾斜率增大,响应时间急剧增加。
接着看吞吐量,随着并发用户数的增加,吞吐量增加,进入重压力区后逐步平稳,到达拐点区后急剧下降,说明系统已经达到了处理极限,有点要扛不住的感觉。
同理,随着并发用户数的增加,资源利用率逐步上升,最后达到饱和状态。
最后,把所有指标融合到一起来分析,随着并发用户数的增加,吞吐量与资源利用率增加,说明系统在积极处理,所以响应时间增加得并不明显,处于比较好的状态。但随着并发用户数的持续增加,压力也在持续加大,吞吐量与资源利用率都达到了饱和,随后吞吐量急剧下降,造成响应时间急剧增长。轻压力区与重压力区的交界点是系统的最佳并发用户数,因为各种资源都利用充分,响应也很快;而重压力区与拐点区的交界点就是系统的最大并发
用户数,因为超过这个点,系统性能将会急剧下降甚至崩溃。
地铁模型
假设:
某地铁站进站只有3个刷卡机。
人少的情况下,每位乘客很快就可以刷卡进站,假设进站需要1s。
乘客耐心有限,如果等待超过30min,就暴躁、唠叨,甚至放弃。
场景一:只有1名乘客进站时,这名乘客可以在1s的时间内完成进站,且只利用了一台刷卡机,剩余2台等待着。
场景二:只有2名乘客进站时,2名乘客仍都可以在1s的时间内完成进站,且利用了2台刷卡机,剩余1台等待着。
场景三:只有3名乘客进站时,3名乘客还能在1s的时间内完成进站,且利用了3台刷卡机,资源得到充分利用。
场景四:A、B、C三名乘客进站,同时D、E、F乘客也要进站,因为A、B、C先到,所以D、E、F乘客需要排队。
那么,A、B、C乘客进站时间为1s,而D、E、F乘客必须等待1s,所以他们3位在进站的时间是2s。
场景五:假设这次进站一次来了9名乘客,有3名的“响应时间”为1s,有3名的“响应时间”为2s(等待1s+进站1s), 还有3名的“响应时间”为3s(等待2s+进站1s)。
场景六:如果地铁正好在火车站,每名乘客都拿着大小不同的包,包太大导致卡在刷卡机堵塞,每名乘客的进站时 间就会又不一样。刷卡机有加宽的和正常宽度的两种类型,那么拿大包的乘客可以通过加宽的刷卡机快速进站(增 加带宽)。
场景七:进站的乘客越来越多,3台刷卡机已经无法满足需求,为了减少人流的积压,需要再多开几个刷卡机,增 加进站的人流与速度(提升TPS、增大连接数)。
![]() 喜欢
喜欢
0
![]() 赠金笔
赠金笔