 加载中…
加载中…NiFi入门:Kafka数据同步到关系数据库(PostgreSQL)--Part3
标签:
nifi |
分类: NiFi |
原文我发布在天善论坛
Part1和Part2把如何使用EvaluateJsonPath获取属性值,SplitJson
拆分行数据说清楚了,还差Kafka源的部分.
Kafka源的设置:
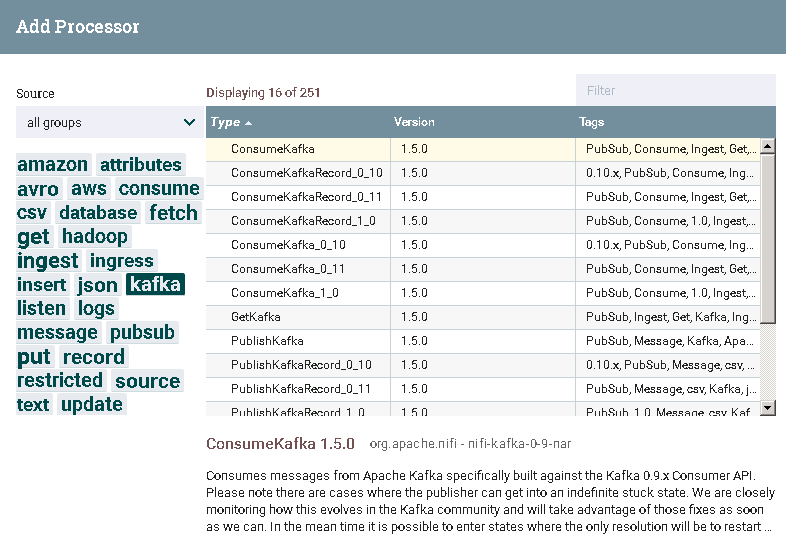
NiFi中对应Kafka有不同版本,
分队对应0.9,0.10,0.11和1.0的不同Kafka版本,低版本的process可以处理高版本的Kafka
https://ask.hellobi.com/uploads/article/20180815/dcb61216c280cec9784e37bbb2735cc0.PNG
{kind=link}
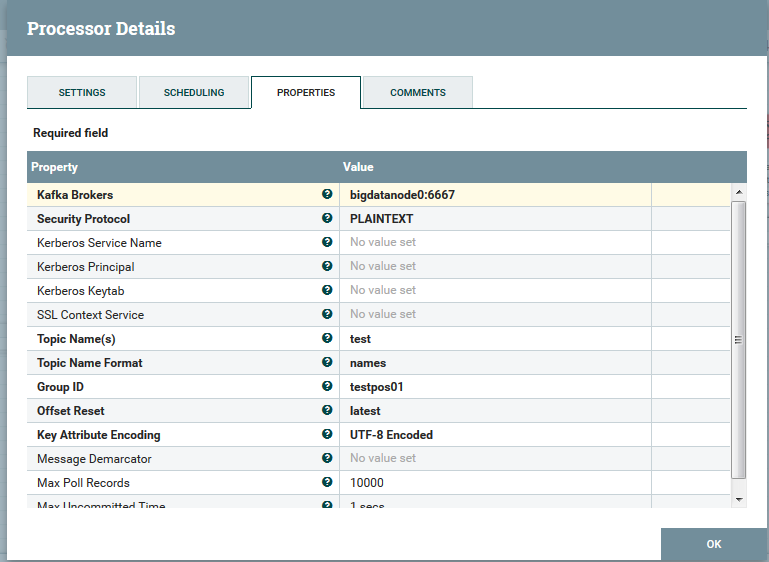
HDP用的Kafka0.10的版本,我使用了ConsumeKafka_0_10,注意groupid不用和其他用的process重复,不然会被消费掉.
https://ask.hellobi.com/uploads/article/20180815/8a55b3605792b92b0391addf215e03f5.PNG
{kind=link}
进一步思考:
1. 判断记录是否符合格式
增加了属性判断:使用RouteOnAttribute判断trx_num属性是否非空
${trx_num:isEmpty():not()}
防止完成后的概览图:
https://ask.hellobi.com/uploads/article/20180815/b06d1ec2b1308de12b9eb355bdb65641.PNG
{kind=link}
2.考虑使用record模式
attribute模式给了用户很多自由度,但是也导致了,属性要多次配置,record模式比较好的解决了这个模式,通过统一定义schema,
从Kafka端就可以很好的解构
3. flowfile的合并
现在putsql是一行一行的作insert, 记录数不多还好,多的话对性能影响较大.并且如果是往其他目标insert(如hdfs\mogndo)等, 需要配合mergercontent组件完成.![]() 喜欢
喜欢
0
![]() 赠金笔
赠金笔