 加载中…
加载中…正态分布&概率密度函数
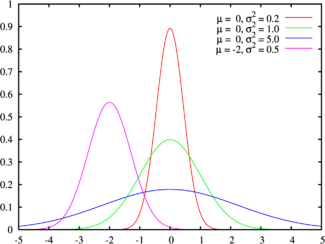
正态分布曲线反映了随机变量的分布规律。理论上的正态分布曲线是一条中间高,两端逐渐下降且完全对称的钟形曲线
正态分布(Normal distribution)又名高斯分布(Gaussian distribution),是一个在数学、物理及project等领域都很重要的概率分布,在统计学的很多方面有着重大的影响力。
若随机变量X服从一个数学期望为μ、标准方差为σ2的高斯分布,记为:
- X∼N(μ,σ2),
则其概率密度函数为
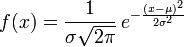{kind=link}
{kind=link}
正态分布中一些值得注意的量:
标准偏差
{kind=link}
http://www.360doc.com/content/17/0306/13/32342759_634411464.shtml什么是正态分布
正态概率分布是连续型随机变量概率分布中最重要的形式,它在实践中有着广泛的应用。在生活中有许多现象的分布都服从正态分布,如人的身高、体重、智商分数;某种产品的尺寸和质量;降雨量;学习成绩,特别是,在统计推断时,当样本的数量足够大时,许多统计数据都服从正态分布。下面以人的身高为例,通俗解释一下什么是正态分布?
随机抽取200位同等年龄上下的男性,测量好他们的身高之后计算出平均身高,通过将平均身高和他们各自的身高对比,我们可以轻松发现这一现象:大多数男性的身高都集中在平均身高上下浮动,有极少数男性身高很矮,也有极少数男性身高很高。这200为男性身高的概率密度函数可能如下图所示:
http://image104.360doc.com/DownloadImg/2017/03/0613/93172330_1
实际上,这种形状十分常见,应用很广泛,它叫做正态分布。
正态分布的概率密度函数
正态分布之所以被称为正态,是因为它的形态看起来合乎理性。在现实生活中,遇到测量值之类的大量连续数据时,正常情况下都会期望看到这种形态。正态分布的概率密度函数的计算公式如下:
http://image104.360doc.com/DownloadImg/2017/03/0613/93172330_2
其中μ=均值,σ=标准差,π=3.14159,e=2.71828。如果随机变量X符合上述概率密度函数的分布,则称X是服从参数为μ,σ2的正态分布,记为X~N(μ,σ2)。
http://image104.360doc.com/DownloadImg/2017/03/0613/93172330_3
正态分布的概率密度函数具有下列性质;
-
以x=μ为对称轴的对称分布;
-
σ2指分散性,σ2值越大,正态分布的曲线越扁平、越宽;
-
-
以x轴为渐近线;
-
若随机变量X1,X2…,Xn皆服从正态分布,且相互独立,则对任意几个常数a1,a2,…,an(不全为0),Z=a1X1+a2x2+……+anXn也服从正态分布。
-
正态分布求概率
在《每天一点统计学——概率密度函数》中,我们已经知道如何使用概率密度函数求概率的方法。但是在正态分布中求概率是非常困难的,提供包括所有不同的μ和σ的正态分布表也是不可能的。所以统计学家通过一种简单的方法来解决这一问题。对于一个随机变量X~N(μ,σ2),如果令Z=(x-μ)/σ(标准分),则随机变量Z服从μ=0,σ2=1的正态分布,记为Z~N(0,1),称为标准正态分布。
标准正态分布的概率密度函数为:
http://image104.360doc.com/DownloadImg/2017/03/0613/93172330_4
-
例子:已知研究生完成一篇硕士论文的时间服从正态分布,平均花费2500h,标准差为400h,现随机找到一个已完成论文的学生,求:
(1)他完成论文的时间超过2700h的概率;
(2)他完成论文的时间低于2000h的概率;
(3)他完成论文的时间在2400h~2600h之间的概率。
解:用X表示完成论文的时间,则X~N(2500,400*400)。这是非标准的正态分布,如果直接计算概率是非常麻烦的,我们首先将其转化为标准正态分布,然后通过标准正态分布表查出变量的概率值。
(1)求P(X>2700)
Z=(x-μ)/σ=(2700-2500)/400=0.5
-
(2)求P(X<>
Z=(x-μ)/σ=(2000-2500)/400=-1.25
根据正态分布的对称性,1.25的概率值与-1.25的概率值完全对称,所以只查1.25的概率值即可。Z=1.25时,P(1.25)=0.8944,则P(-1.25)= 1-P(1.25)=0.1056
(3)求P(2400<><>
Z1=(x-μ)/σ=(2600-2500)/400=0.25
Z2=(x-μ)/σ=(2400-2500)/400=-0.25
查询标准正态分布概率表,可得出P(0.25) = 0.5987,P(-0.25) = 0.4013。
P(2400<><><2600) -=""><2400) =="" 0.5987="" -="" 0.4013="">
在某次数学考试中,考生的成绩http://pic2.mofangge.com/upload/papers//20140823/20140823125453019186.gif~N(90,100).
(1)试求考试成绩http://pic2.mofangge.com/upload/papers//20140823/20140823125453019186.gif位于区间(70,110)上的概率是多少?
(2)若这次考试共有2
000名考生,试估计考试成绩在(80,100)间的考生大约有多少人?
{kind=link}
| 1)0.954 4(2)1 365人 |
| ∵http://pic2.mofangge.com/upload/papers//20140823/20140823125453253251.gif="10. (1)由于正态变量在区间(http://pic2.mofangge.com/upload/papers//20140823/20140823125453019186.gif位于区间(70,110)内的概率就是0.954 4. (2)由http://pic2.mofangge.com/upload/papers//20140823/20140823125453237180.gif="100. 由于正态变量在区间(http://pic2.mofangge.com/upload/papers//20140823/20140823125453237180.gif)内取值的概率是0.682 6, 所以考试成绩http://pic2.mofangge.com/upload/papers//20140823/20140823125453019186.gif位于区间(80,100)内的概率是0.682 6. 一共有2 000名考生,所以考试成绩在(80,100)间的考生大约有2 000×0.682 6≈1 365(人). |
{kind=link}
{kind=link}
![]() 喜欢
喜欢
0
![]() 赠金笔
赠金笔