 加载中…
加载中…最优化问题求解之:遗传算法
| 分类: 算法与数据结构 |
遗传算法的手工模拟计算示例
为更好地理解遗传算法的运算过程,下面用手工计算来简单地模拟遗传算法的各
http://www.elecfans.com/article/UploadPic/2008-12/200812202481225480.jpg
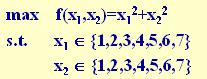{kind=link}
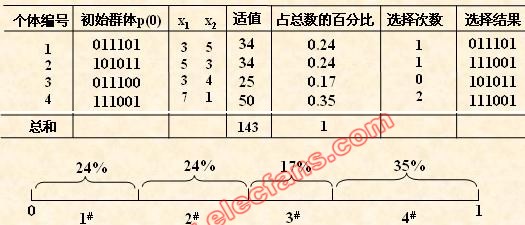
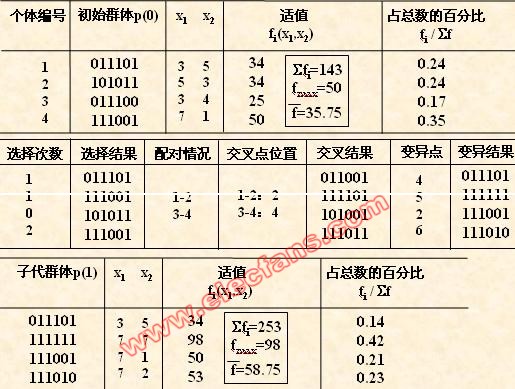
(2) 初始群体的产生
本例中,我们采用与适应度成正比的概率来确定各个个体复制到下一代群体中
http://www.elecfans.com/article/UploadPic/2008-12/200812202485936734.jpg
{kind=link}
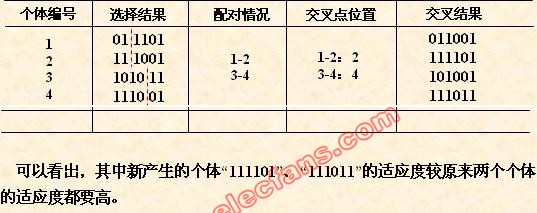
(5)
http://www.elecfans.com/article/UploadPic/2008-12/200812202493093964.jpg
{kind=link}
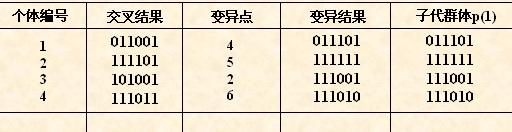
(6)
http://www.elecfans.com/article/UploadPic/2008-12/200812202495948037.jpg
{kind=link}
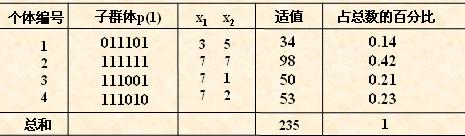
对群体P(t)进行一轮选择、交叉、变异运算之后可得到新一代的群体p(t+1)。
http://www.elecfans.com/article/UploadPic/2008-12/200812202502724016.jpg
{kind=link}
从上表中可以看出,群体经过一代进化之后,其适应度的最大值、平均值都得
[注意]
http://www.elecfans.com/article/UploadPic/2008-12/20081220251181281.jpg
{kind=link}
----------------------------------------------------------------------------
遗传算法属于进化算法( Evolutionary Algorithms) 的一种,它通过模仿自然界的选择与遗传的机理来寻找最优解. 遗传算法有三个基本算子:选择、交叉和变异.
。数值方法求解这一问题的主要手段是迭代运算。一般的迭代方法容易陷入局部极小的陷阱而出现"死循环"现象,使迭代无法进行。遗传算法很好地克服了这个缺点,是一种全局优化算法。
生物在漫长的进化过程中,从低等生物一直发展到高等生物,可以说是一个绝妙的优化过程。这是自然环境选择的结果。人们研究生物进化现象,总结出进化过程包括复制、杂交、变异、竞争和选择。一些学者从生物遗传、进化的过程得到启发,提出了遗传算法(GA)。算法中称遗传的生物体为个体(individual),个体对环境的适应程度用适应值(fitness)表示。适应值取决于个体的染色体(chromosome),在算法中染色体常用一串数字表示,数字串中的一位对应一个基因(gene)。一定数量的个体组成一个群体(population)。对所有个体进行选择、交叉和变异等操作,生成新的群体,称为新一代(new generation)。
遗传算法计算程序的流程可以表示如下[3]:
第一步 准备工作
(1)选择合适的编码方案,将变量(特征)转换为染色体(数字串,串长为m)。通常用二进制编码。
(2)选择合适的参数,包括群体大小(个体数M)、交叉概率PC和变异概率Pm。
(3)确定适应值函数f(x)。f(x)应为正值。
第二步 形成一个初始群体(含M个个体)。在边坡滑裂面搜索问题中,取已分析的可能滑裂面组作为初始群体。
第三步 对每一染色体(串)计算其适应值fi,同时计算群体的总适应值 。
第四步 选择
计算每一串的选择概率Pi=fi/F及累计概率。选择一般通过模拟旋转滚花轮(roulette,其上按Pi大小分成大小不等的扇形区)的算法进行。旋转M次即可选出M个串来。在计算机上实现的步骤是:产生[0,1]间随机数r,若r
第五步 交叉
(1)对每串产生[0,1]间随机数,若r>pc,则该串参加交叉操作,如此选出参加交叉的一组后,随机配对。
(2) 对每一对,产生[1,m]间的随机数以确定交叉的位置。
第六步 变异
如变异概率为Pm,则可能变异的位数的期望值为Pm ×m×M,每一位以等概率变异。具体为对每一串中的每一位产生[0,1]间的随机数r,若r
如新个体数达到M个,则已形成一个新群体,转向第三步;否则转向第四步继续遗传操作。直到找到使适应值最大的个体或达到最大进化代数为止。
由于选择概率是由适应值决定的,即适应值大的染色体入选概率也较大,使选择起到"择优汰劣"的作用。交叉使染色体交换信息,结合选择规则,使优秀信息得以保存,不良信息被遗弃。变异是基因中得某一位发生突变,以达到产生确实有实质性差异的新品种。遗传算法虽是一种随机算法,但它是有导向的,它所使用的"按概率随机选择"方法是在有方向的搜索方法中的一种工具。正是这种独特的搜索方法,使遗传算法自然地避开了其它最优化算法常遇到的局部最小陷阱。
遗传算法的优点:
1. 与问题领域无关切快速随机的搜索能力。
2. 搜索从群体出发,具有潜在的并行性,可以进行多个个体的同时比较,robust.
3. 搜索使用评价函数启发,过程简单
4. 使用概率机制进行迭代,具有随机性。
5. 具有可扩展性,容易与其他算法结合。
遗传算法的缺点:
zzfrom:
![]() 喜欢
喜欢
0
![]() 赠金笔
赠金笔