 加载中…
加载中…常用归一化(标准化)方法(线性归一化、0均值归一化)
| 分类: 数据处理 |
1). 线性归一化,线性归一化会把输入数据都转换到[0
1]的范围,公式如下
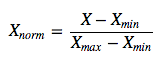{kind=link}
该方法实现对原始数据的等比例缩放,其中Xnorm为归一化后的数据,X为原始数据,Xmax、Xmin分别为原始数据集的最大值和最小值。
适用于数值比较集中的情况,可使用经验值常量来来代替max,min
优点:通过利用变量取值的最大值和最小值将原始数据转换为界于某一特定范围的数据,从 而消除量纲和数量级的影响
适用于经过处理后符合标准正态分布,即均值为0,标准差为1
缺点:由于极值化方法在对变量无量纲化过程中仅仅与该变量的最大值和最小值这两个极端
值有关,而与其他取值无关,这使得该方法在改变各变量权重时过分依赖两个极端取值。
2)零均值归一化(zero-mean normalization):
将原始数据集归一化为均值为0、方差1的数据集,归一化公式如下:
https://images2015.cnblogs.com/blog/743682/201511/743682-20151108155308414-1556013345.png
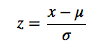{kind=link}
其中,μ、σ分别为原始数据集的均值和方法。该种归一化方式要求原始数据的分布可以近似为高斯分布,否则归一化的效果会变得很糟糕。
优点:去量纲化
缺点:这种归一化方式要求原始数据的分布可以近似为高斯分布,否则归一化的效果会变得 很糟糕。
3)
非线性归一化
使用非线性函数log、指数、正切等,如y = 1-e^(-x),在x∈[0,
6]变化较明显, 用在数据分化比较大的场景
适用于在实际工程中,经常会有类似点击次数/浏览次数的特征,这类特征是长尾分布的,可以将其用对数函数进行压缩。特别的,在特征相除时,可以用对数压缩之后的特征相减得到。
![]() 喜欢
喜欢
0
![]() 赠金笔
赠金笔