 加载中…
加载中…
IEEE/CAAJAS:基于对比学习的退化特定的盲超分网络
标签:
it |
单张图像超分辨率任务致力于从一张低分辨率输入中恢复出高分辨率图像。该任务是医疗诊断、目标检测与识别等高级计算机视觉任务的先决条件之一。近年来,基于深度神经网络的超分辨率方法成为了该领域的研究热点。
作为一个病态难的逆问题,图像超分辨率任务通常与图像退化过程高度耦合。现有流行的单张图像超分问题的解决策略是:假定退化过程已知且固定,进而构造深度神经网络并通过数据驱动进行超分重构。因而,在相同退化过程评估的情况下,这类方法实现了客观指标结果的不断提升。然而,在真实场景中,由于成像和传输过程,图像退化模型通常多样且未知。现有单张超分算法中所采用的简单退化假设,与实际输入的退化之间往往不匹配。因而,即使退化过程稍有不同,这些方法的性能就会严重下降。这就给这些数据驱动的方法在实际应用中带来了困难。因此,近年来学者们开始关注退化过程未知的盲超分辨率问题,试图解决更加实际的超分问题。
武汉大学电子信息学院马佳义教授团队提出一种基于对比学习的退化特定的盲超分网络(CRDNet)。该网络考虑全局先验并将其嵌入到超分网络中感知退化特性,同时利用对比学习约束来缓解过度平滑的预测结果,实现了先进的超分性能。研究成果发表于IEEE/CAA
Journal of Automatica Sincia 2023年第十卷第一期:X. Y. Wang, J. Y. Ma, and
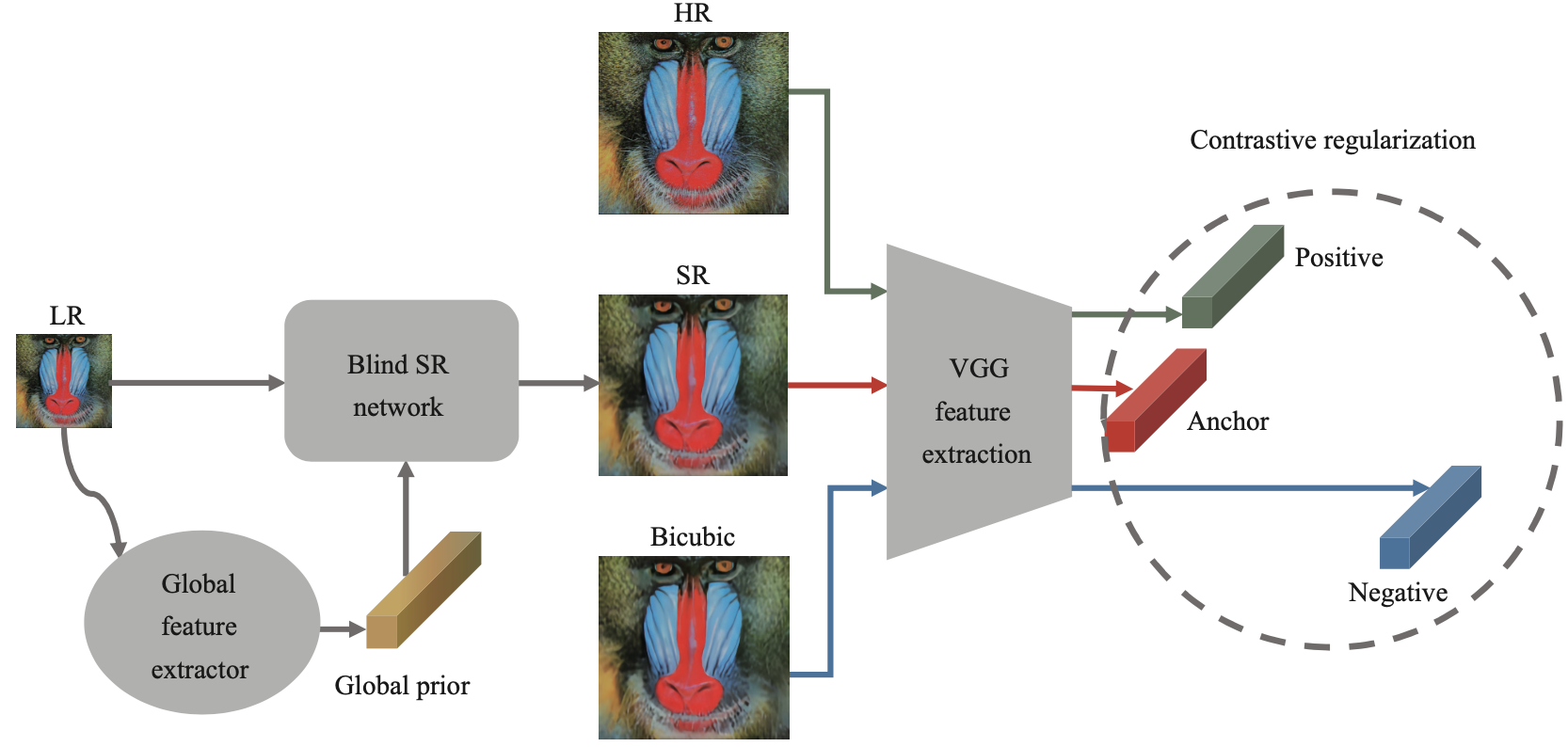
首先,避免像现有算法中学习模糊核的方式来估计退化模型,CRDNet方法将均值对比归一化系数引入超分辨率网络中以提取全局先验信息,旨在捕获面向退化失真的全局统计特性,使得所设计的盲超分网络能适应失真的变化。由于取代了模糊核的估计,本文的方法避免了估计误差的累积,同时不需要为监督学习提供真实的模糊核。其次,为了实现性能和参数之间的最佳权衡,CRDNet中设计了一个紧凑的盲超分网络,采用上下采样策略在低维空间进行密集卷积计算。与其他涉及模糊核和超分结果迭代估计的两步方法相比,本文的方法简单且省时。最后,为了减轻由像素损失引起的过度平滑的效果,本文通过三重损失对结果图像进行对比学习的约束。如图3所示。预期中,对比学习会将超分辨率结果拉近高分辨率图像,推离特征域中的负样本,这将有利于盲超分预测更加清晰。此外,对比学习的约束在提高了盲超分辨率的性能的同时无需在推理过程中增加额外的计算负担和参数。相较于现有的盲超分辨率先进算法,本文的方法实现了最优的参数和性能的权衡。
http://image.sciencenet.cn/home/202304/21/150607skuuunmupvoq8auq.png
{kind=link}
图1
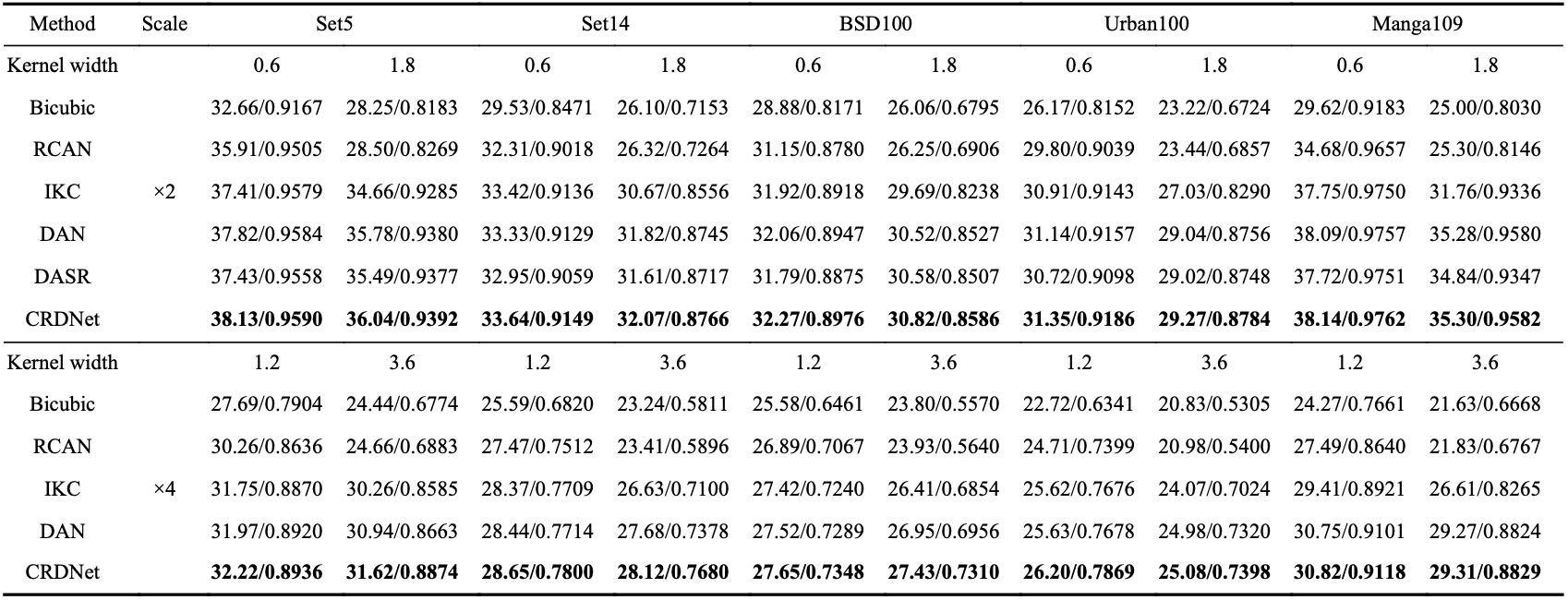
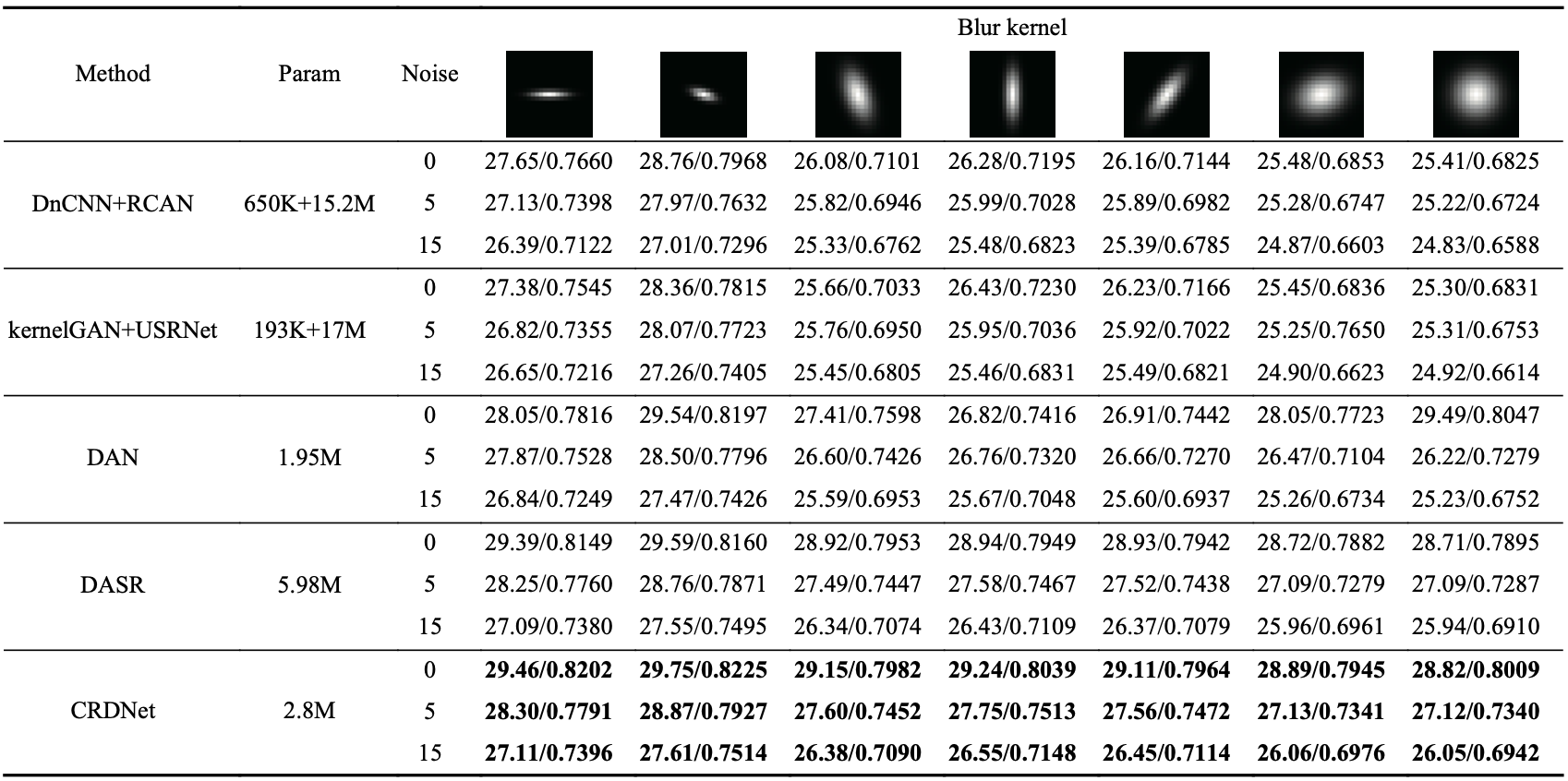
所提出的方法在多种退化上的测试结果如表1和表2所示,从实验看出,该方法能实现更优且均衡的效果。超分辨率可视化结果如图2和图3所示。
表1
http://image.sciencenet.cn/home/202304/21/150620b36646ma6hhqa4s6.png
{kind=link}
表2
http://image.sciencenet.cn/home/202304/21/150634ow11qhu16081yi0u.png
{kind=link}
http://image.sciencenet.cn/home/202304/21/150701kxaps6hsppxzgpsp.jpg
{kind=link}
图2
http://image.sciencenet.cn/home/202304/21/150716gtyaz1ib9wb6abzm.png
{kind=link}
图3
最后,本文将方法应用于真实场景图像中,超分辨率可视化结果如图4所示。
http://image.sciencenet.cn/home/202304/21/150730xkmzaoipokpmo7a2.png
{kind=link}
图4
http://image.sciencenet.cn/home/202304/21/150742kotho9hzhjggu57q.png
{kind=link}
王歆雅,武汉大学电子信息学院博士研究生。研究方向包括深度学习,图像超分辨率等。
http://image.sciencenet.cn/home/202304/21/150801gk5jbqqawqmjwaxm.png
{kind=link}
马佳义,武汉大学教授。2014年博士毕业于华中科技大学。主要研究方向包括计算机视觉、机器学习和模式识别。被列入科睿唯安2019-2022年全球高被引科学家名单。已发表了300余篇学术论文,包括IEEE TPAMI/TIP、IJCV、CVPR、ICCV、ECCV等。担任SCI期刊Information Fusion区域编辑、Neurocomputing等期刊编委。
http://image.sciencenet.cn/home/202304/21/150816lai6xa9i6688r7x8.png
{kind=link}
江俊君,哈尔滨工业大学教授。2014年博士毕业于武汉大学。主要研究方向包括计算机视觉、机器学习和模式识别。2017年入选ICME最佳论文提名。曾获MMM 2015最佳学生论文亚军,2016年中国计算机学会(CCF)优秀博士论文奖,2015年ACM武汉博士论文奖。
感谢本文作者提供以上简介
![]() 喜欢
喜欢
0
![]() 赠金笔
赠金笔