 加载中…
加载中…【精选导读】模型分类和医学影像分析
标签:
it |
本期推荐4篇模型分类和医学影像分析相关好文
[1] Z. W. Zhang, S. T. Ye, Y. R. Zhang, W. P. Ding, and H. Wang,
“Belief Combination of Classifiers for
Incomplete Data,”
[2] X. Chen, M. Yu, F. Yue, and B. Li,
“Orientation Field Code Hashing: A
Novel Method for Fast Palmprint
Identification,”
[3] E. F. Ohata, G. M. Bezerra, J. V.
S. Chagas, A. V. Lira Neto, A. B. Albuquerque, V. H. C.
Albuquerque, and P. P. Rebouças Filho,“Automatic Detection of COVID-19
Infection Using Chest X-ray Images Through Transfer
Learning,”
[4] Y. Liu, Y. Shi, F. H. Mu, J.
Cheng, and X. Chen, “Glioma Segmentation-oriented
Multi-modal MR Image Fusion with Adversarial
Learning,”
不完全数据分类器的置信组合
1.
分类是数据分析中一个传统且普遍存在的问题,其目的是将对象识别为它们所属的类别。
但是,大多数的方法,如删除法、基于模型的方法和估计方法,只处理缺失值,不考虑缺失值对分类的负面影响。虽然基于机器学习的方法可以对缺失值进行分类,但由于没有考虑缺失值在分类过程中产生的不确定性,因此其性能较差,并且鲁棒性不足。此外,现有方法主要集中在测试集上,并且在大多数情况下假设训练集是完整的。当训练集不完整时,对不完整模式进行补全或直接删除。这些方法倾向于直接建模缺失值,如估计策略或模型预测。然而,这将带来新的不确定性。
2.
针对在训练集和测试集都存在大量缺失值的情况下,如何在不丢失信息的情况下提高不完整数据的分类精度,以及如何引入新的不确定性信息?
该项研究工作基于以下三个方面:与删除方法相比,研究一种不删除任何观察信息的方法,因为这些信息可能是有价值的;与基于模型和估计的方法相比,开发一种不引入新的不确定性的方法,因为统计假设会导致不确定性;与机器学习方法相比,目标是通过考虑不确定性和不精确性的缺失值建模来提高分类性能。在BCC中,不同的属性被视为独立的源,每个属性的集合被视为一个子集。然后,使用每个子集单独训练多个分类器,并允许每个观察到的属性为查询模式提供子分类结果。最后,使用这些不同权重(平衡因子)的子分类结果提供补充信息,共同确定查询模式的最终类别。权重由两个方面组成:全局和局部,利用优化函数计算出的全局权值来表示各分类器的可靠性,利用挖掘属性分布特征得到的局部权值来量化观察属性对模式分类的重要性。
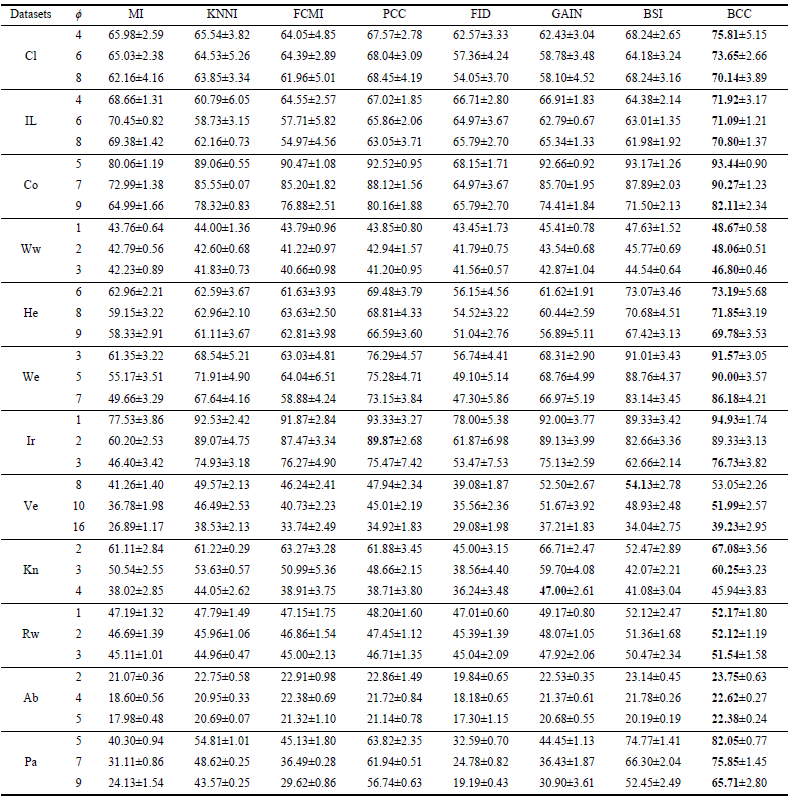
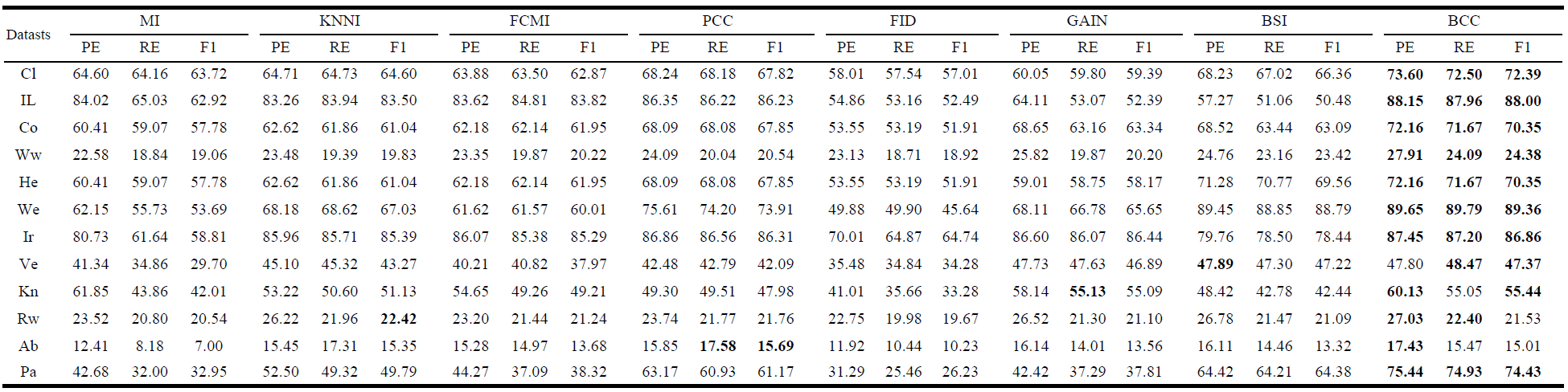
为了验证BCC方法面对缺失数据的有效性,在多个基准数据集与其他几种传统方法进行了比较:分别采用四种评测标准对算法性能进行评估,即准确度(AC)、精确度(PE)、召回率(RE)和F1-measure (F1)。实验采用2折交叉验证。由于训练集和测试集的大小相等,所以所有的模式都可以在每一次折叠上分别进行训练和测试。该程序随机运行10次,BCC的性能显示在各种情况下,表示每个训练和测试模式的缺失值的数量。本导读为方便起见,只展示基于K近邻的算法性能比较结果,算法分类准确度结果如表1所示,其它指标PE、RE、F1汇总在表2中。可以看出,在大多数情况下,BCC方法通常比其他常规方法有更好的结果。作为典型的单插补策略,其它方法根据不同的机制预测可能的缺失值估计可能不够合理。例如,在KNNI中,相似模式(邻居)被用来估算缺失值。在这种情况下,相似性度量范数的选择是一个必不可少的过程,如果选择了不适当的措施,结果往往不理想。此外,直接建模缺失值的缺点是,由于估计无法取代现实特征,因此不可避免带来新的不确定性。值得注意的是,仅对缺失值建模是不够的,因为缺失值带来的不确定性也会对分类器的性能产生负面影响。相比之下,本文算法在多种不同评测标准中,大多数情况下均能取得较优异的实验性能,充分证明其有效性。
表1
http://image.sciencenet.cn/home/202209/16/164740su80thxv82vm0e6p.png
{kind=link}
表2
http://image.sciencenet.cn/home/202209/16/164814cecih6ske6zfruir.png
{kind=link}
3.
Zuowei
Zhang,
Songtao
Ye,
Yifu
Zhang,
Weiping
Ding,
Hao
Wang,
方向域编码哈希:一种快速掌纹识别的新方法
1.
掌纹识别系统因其可靠的安全性能而备受推崇,是生物特征识别研究的热点,已成为高度安全的个人认证系统的理想解决方案之一,并已成功应用于多个领域的门禁。现有掌纹识别方法可以大致划分为沿着传统和深度学习的研究思路进展,如基于纹理的掌纹识别、基于方向编码的掌纹识别、基于局部描述符的掌纹识别、基于深度神经网络的掌纹识别。然而,随着注册数的增加,识别准确率和速度趋于下降,这就需要快速的识别系统来满足大规模用户的需求。因此,加快识别过程不仅可以减少系统响应时间,而且可以通过采用更复杂的匹配算法来提高识别精度。现有的快速掌纹识别研究大致可以分为四类:层次匹配、掌纹分类、基于树的识别和基于哈希的识别。
在众多的掌纹识别中,基于深度学习的掌纹识别能够获得当前的最好识别性能。尽管一些基于深度神经网络的掌纹识别方法被认为是很不错且有前景的方法,但它们需要大量的样本进行训练。对于掌纹识别,很难采集到足够的掌纹图像,网络泛化能力较差。此外,基于这些方法的特征提取和匹配非常耗时。例如,基于卷积神经网络提取掌纹特征,为了获得匹配分数,需要计算两个特征向量之间的余弦相似度。
2.
为实现大规模掌纹识别的快速识别和验证,河北工业大学Ming Yu教授、北京市科学技术研究院模式识别重点实验室Bin Li教授等提出了一种用于掌纹快速识别的无监督哈希方法,即方向场码哈希法,研究成果“Orientation Field Code Hashing: A Novel Method for Fast Palmprint Identification”发表于IEEE/CAA Journal of Automatica Sincia 2021年第8期,DOI: 10.1109/JAS.2020.1003186.
首先,本文引入了一种新的方向特征编码方法——方向场码
{kind=link}
图1.
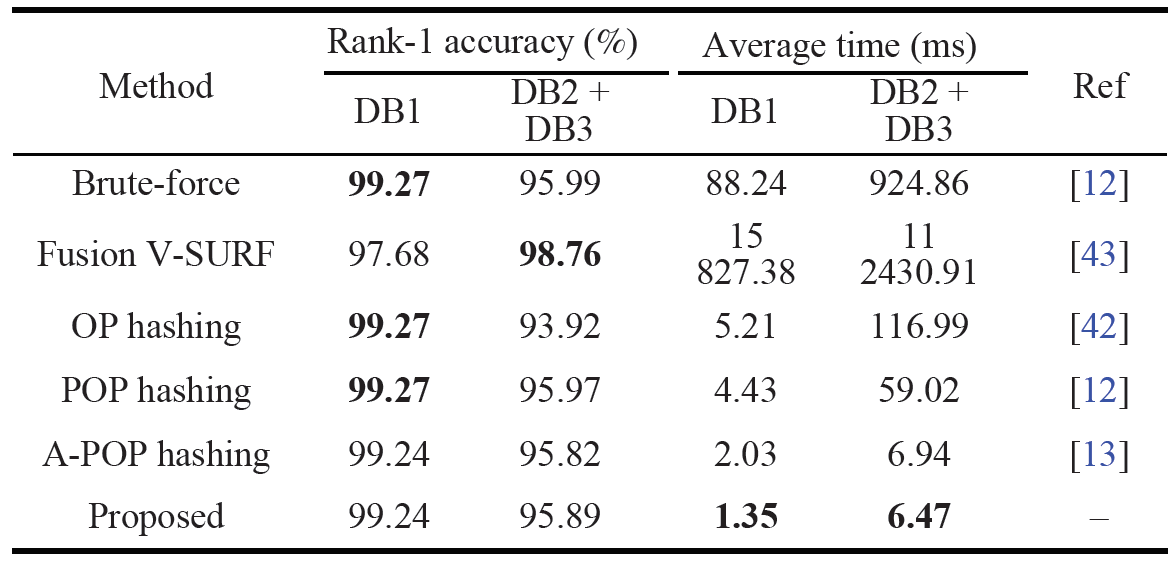
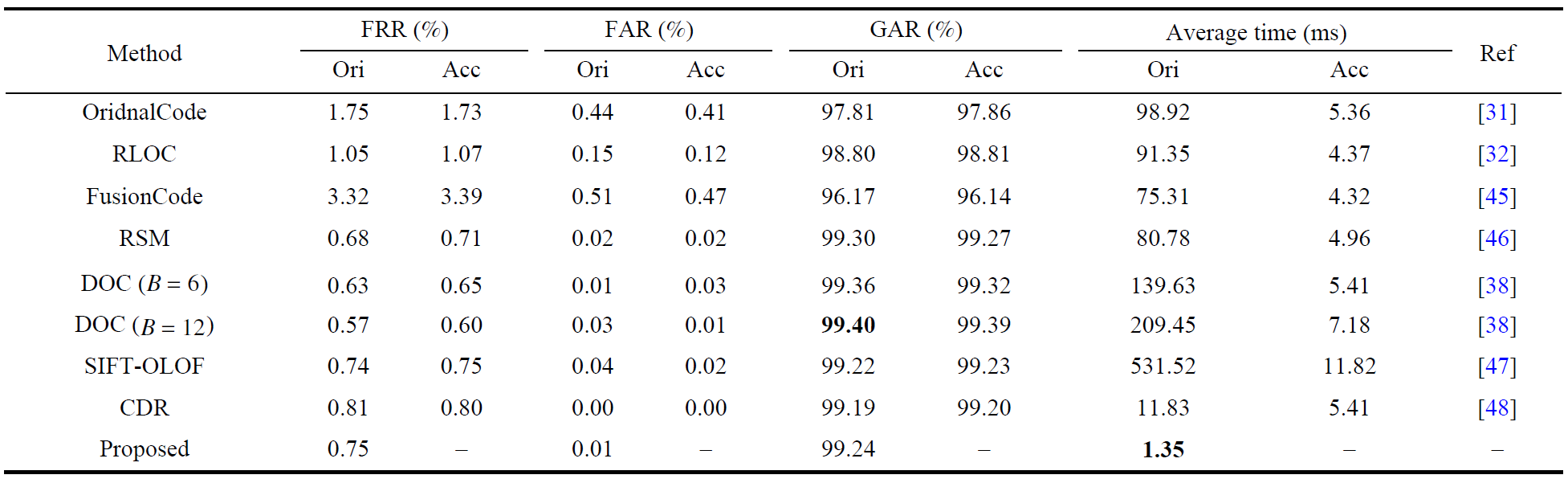
文中通过在三个大规模数据集上的大量实验证明所提出算法的有效性。在Hong Kong PolyU Large-scale Database上,该方法的识别速度比现有最好方法加速约1.35倍,同时在识别性能角度取得了相当精度,具体结果如表1所示,更具体的不同评测标准结果对比如表2所示。在CASIA数据库和合成数据库的联合数据集上,该方法在识别速度上也取得了较好的效果。
表1
http://image.sciencenet.cn/home/202209/16/164933ndacdazgnncpaaau.png
{kind=link}
表2
http://image.sciencenet.cn/home/202209/16/164948mzcxtm6cgtb1o5z4.png
{kind=link}
3.
Xi
Chen,
Ming
Yu,
Feng
Yue,
Bin
Li,
基于迁移学习的胸片自动COVID-19感染检测
1.
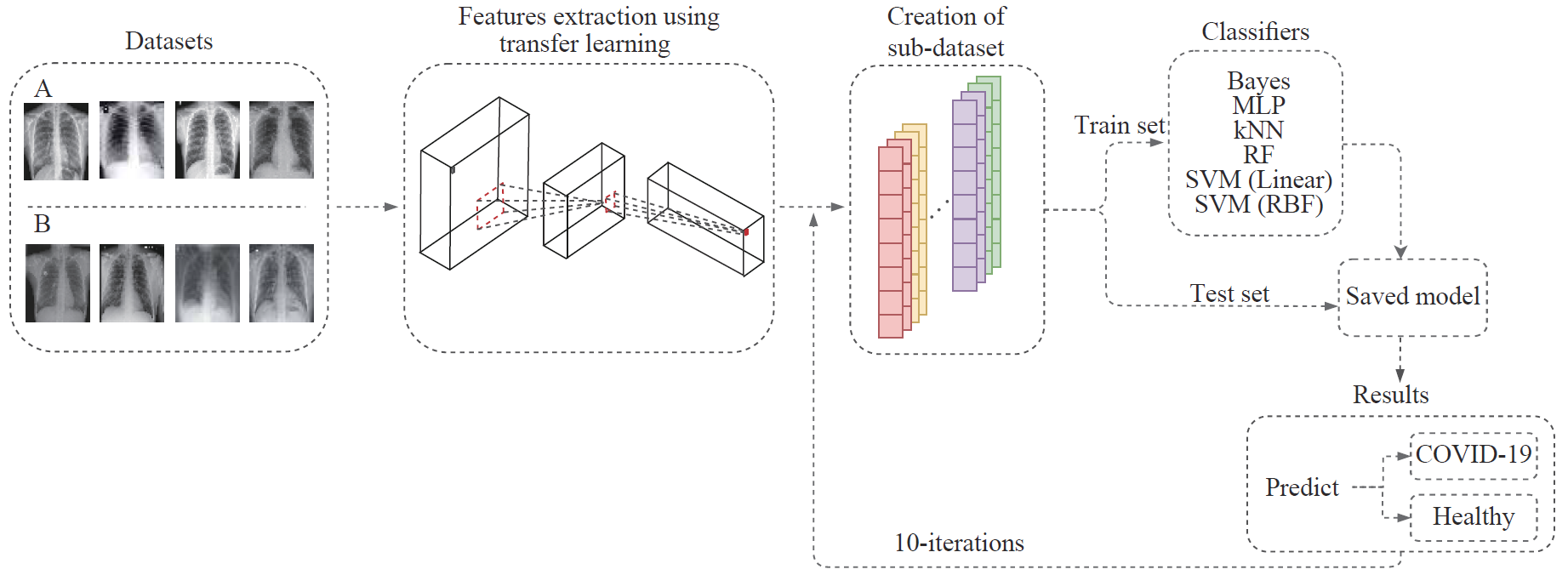
随着世界范围内新技术的发展,病毒检测所需的时间越来越短。基于胸部扫描的COVID-19感染诊断方法,特别是CT扫描,以人工智能的自动图像分析帮助检测、量化和监测COVID-19感染。如何基于CT扫描获得X光影像数据,进而设计基于人工智能的快速识别算法来检测COVID-19病例,成为当前医学影像分析研究的热点和难点问题。
http://image.sciencenet.cn/home/202209/16/165023zixoi908osxa2g0k.png
{kind=link}
图1
2.
为验证多种不同深度学习网络对基于X光影像的自动COVID-19感染检测的效果,巴西Universidade de Fortaleza的Victor Hugo C. de Albuquerque博士等提出一种基于迁移学习的医学影像自动鉴别方法,基于胸片图像对COVID-19感染进行自动检测,研究成果“Automatic Detection of COVID-19 Infection Using Chest X-ray Images Through Transfer Learning”发表于IEEE/CAA Journal of Automatica Sincia 2021年第1期,DOI: 10.1109/JAS.2020.1003393.
本文结合了两个数据集中的12个卷积神经网络和6个分类器,使用在ImageNet上训练的不同架构的卷积神经网络(CNNs),并调整它们作为X射线图像的特征提取器。然后,将CNNs与传统机器学习方法相结合,基于不同CNN网络结构对所搜集的数据进行分类结果如表1所示,和其它基于胸片X光图片分类方法的对比结果如表2所示。大量的实验结果表明,对于其中一个数据集,提取-分类器对的性能最好的是MobileNet架构与SVM分类器使用线性核函数,达到准确率和f1得分为98.462%。对于另一个数据集,最佳配对是带有MLP的DenseNet201,获得95. 64%的准确率和f1得分。
表1
http://image.sciencenet.cn/home/202209/16/165054flz1ll7dmmpl9fc8.png
{kind=link}
表2
http://image.sciencenet.cn/home/202209/16/165111t1rh7trrpr5467ej.png
{kind=link}
3.
Elene
Firmeza Ohata,
Gabriel
Maia Bezerra,
João
Victor Souza das Chagas,
Aloísio
Vieira Lira Neto,
Adriano
Bessa Albuquerque,
Victor
Hugo C. de Albuquerque,
Pedro Pedrosa Rebouças Filho, IFCE助理教授。2015年至2016年在葡萄牙波尔图大学任博士后研究员。主要研究方向包括计算机视觉、医学图像等。
基于对抗学习的胶质瘤分割多模态核磁共振图像融合
1.
在过去的几十年里,医学图像融合在医学影像分析领域成为了研究热点和难点。为突破传统方法的局限性,深度学习已经成为图像融合领域的一个主流,同时也涌现出一系列基于深度学习的医学图像融合方法,如通过卷积神经网络的通用图像融合框架、增强医学图像融合方法、基于双鉴别器条件生成对抗网络的方法等。尽管近年来医学图像融合的研究取得了长足进展,但目前缺乏以临床问题为导向的研究。大多数医学图像融合方法的主要目标是获得具有良好视觉质量和高性能的融合图像,这些融合图像可用于更广泛的图像融合任务(即,不限于医学图像融合),但忽略了相应图像在临床应用中的特定用途,这在很大程度上限制了图像融合方法的实用价值。胶质瘤作为最常见的原发性脑恶性肿瘤,一直严重危害人类健康。在临床实践中,从核磁共振多模态图像中自动分割胶质瘤对本病的诊断和治疗具有重要意义。
2.
得益于基于多模态机器学习的多模态医学图像融合的发展,多模态图像融合取得了目前最优效果,合肥工业大学Yu Liu博士等提出一种基于对抗学习框架的面向胶质瘤分割的多模态磁共振图像融合方法,该方法采用分割网络作为鉴别器,从分割任务的角度来实现更有意义的融合结果。研究成果“Glioma Segmentation-oriented Multi-modal MR Image Fusion with Adversarial Learning”发表于IEEE/CAA Journal of Automatica Sincia 2022年第8期,DOI: 10.1109/JAS.2022.105770
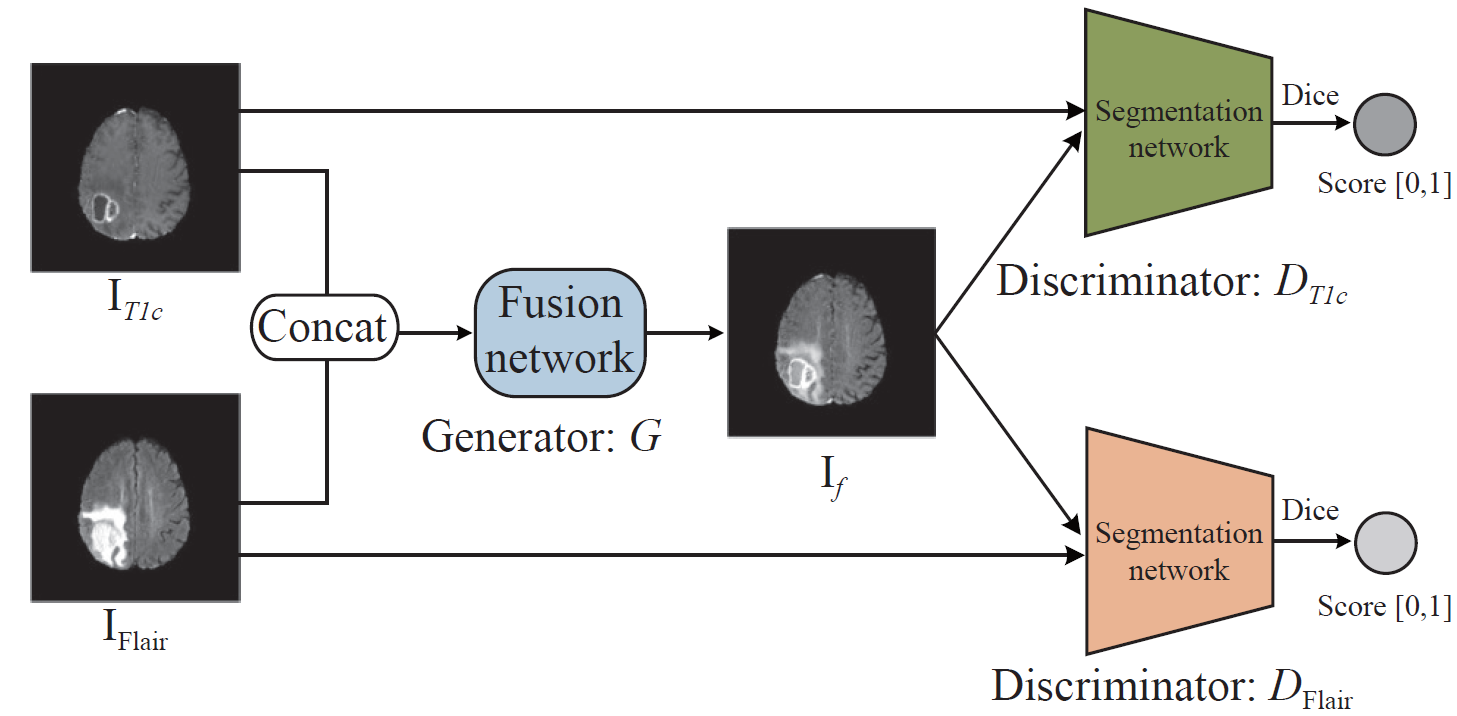
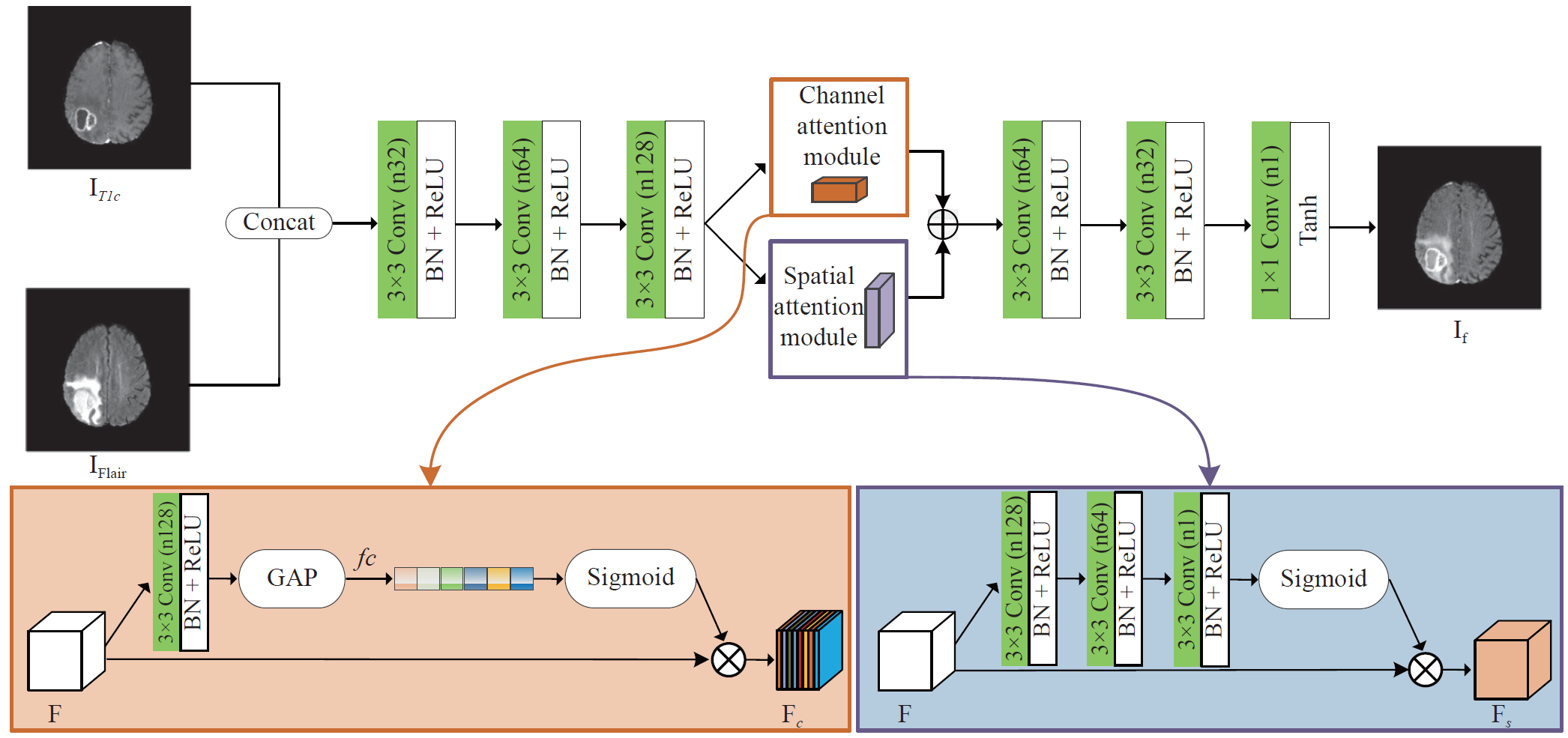
本文主要研究一种面向胶质瘤分割的多模态核心共振图像融合方法与对抗学习策略,通过引入分割网络作为鉴别器来指导融合模型,得到的融合图像在分割任务中更有意义。融合模态可以将多源模态获取的肿瘤不同病理信息整合到一个复合图像中,从而加强它们之间的关联。此算法的基本架构:在胶质瘤分割任务中,对比增强T1加权(T1c)和液体衰减反转恢复(Flair)是两种常用的核磁共振图像模式。前者可以很好地表征肿瘤核心区域,后者可以有效地捕捉肿瘤核心周围的水肿区域。因此,这项工作主要集中在T1c和Flair模式的融合上,提出了一种用于多模态核磁共振图像融合的对抗学习框架。在生成和融合网络设计方面,本文提出在融合后的特征中使用语义分割网络作为鉴别器来区分融合图像和源图像,旨在帮助融合网络(即生成器)从源图像中提取足够的与肿瘤分割相关的病理信息,总体算法架构如图1所示,其中生成器网络结构如图2所示。
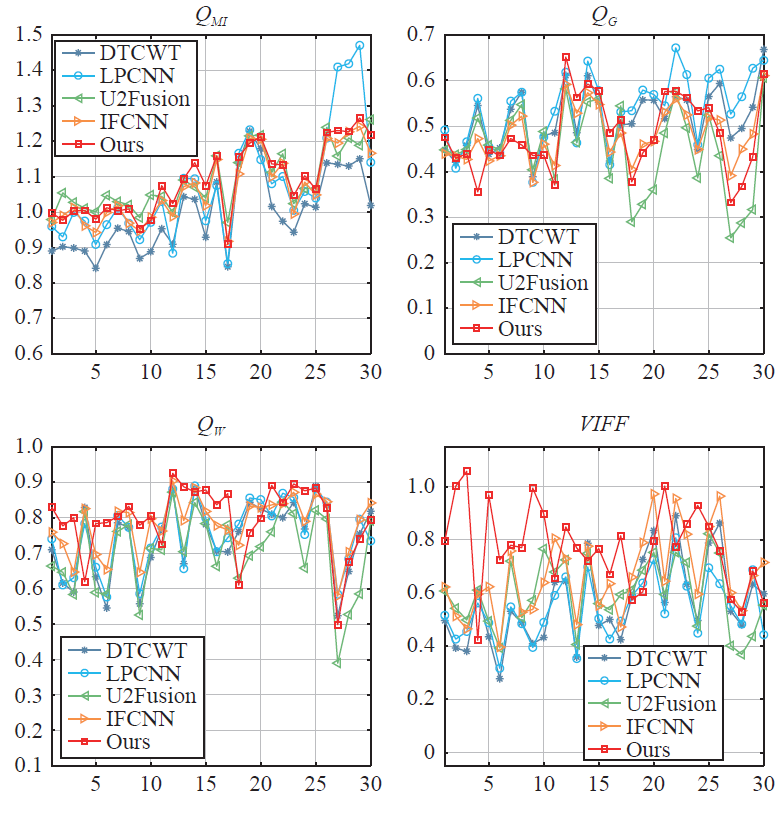
表1列出了不同融合方法使用30个测试样本情况下实验结果。可以看出,本文方法性能高于其他较为先进的四种方法,具有明显的优势。它排名第二,但与表现最好的一款(即U2Fusion)的差距非常小。图3是对不同融合方法的客观性能进行更详细的样本级别的比较。总体而言,本文所提出的方法在多种评价指标上均具有较高的性能,也说明了该方法的融合结果具有更高特质。
http://image.sciencenet.cn/home/202209/16/165206ur23vq2ry883dzvq.png
{kind=link}
图1
http://image.sciencenet.cn/home/202209/16/165219ka9wyrnf9klprnll.png
{kind=link}
图2
表1
http://image.sciencenet.cn/home/202209/16/165234ehnhkj7hm1eexl7z.png
{kind=link}
http://image.sciencenet.cn/home/202209/16/165246v3kkua6q68xzxrq3.png
{kind=link}
图3.
3.
Yu
Liu,
Juan
Cheng,
Xun
Chen,
![]() 喜欢
喜欢
0
![]() 赠金笔
赠金笔