 加载中…
加载中…手把手丨我们在UCL找到了一个糖尿病数据集,用机器学习预测糖尿病
摘要:
根据美国疾病控制预防中心的数据,现在美国1/7的成年人患有糖尿病。但是到2050年,这个比例将会快速增长至高达1/3。我们在UCL机器学习数据库里一个糖尿病数据集,希望可以通过这一数据集,了解如何利用机器学习来帮助我们预测糖尿病,让我们开始吧!
数据集github链接:https://github.com/susanli2016/Machine-Learning-with-Python/blob/master/diabetes.csv
数据
糖尿病数据集可从UCI机器学习库中获取并下载。
https://yqfile.alicdn.com/d4858c5db9582633b5345bbfd4f8cfca12d39c1e.png
{kind=link}
特征(怀孕次数,血糖,血压,皮脂厚度,胰岛素,BMI身体质量指数,糖尿病遗传函数,年龄,结果):
https://yqfile.alicdn.com/dbf88a2a4748c473ff890266b7407fa2274aca52.png
{kind=link}
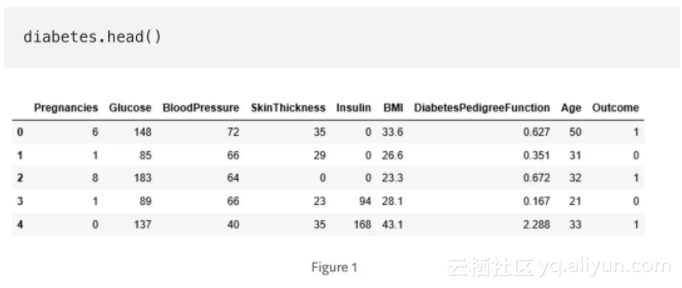
糖尿病数据集由768个数据点组成,各有9个特征:
https://yqfile.alicdn.com/a1ab5bd0b3f6e4f45c3808f92e19fb887f61343c.png
{kind=link}
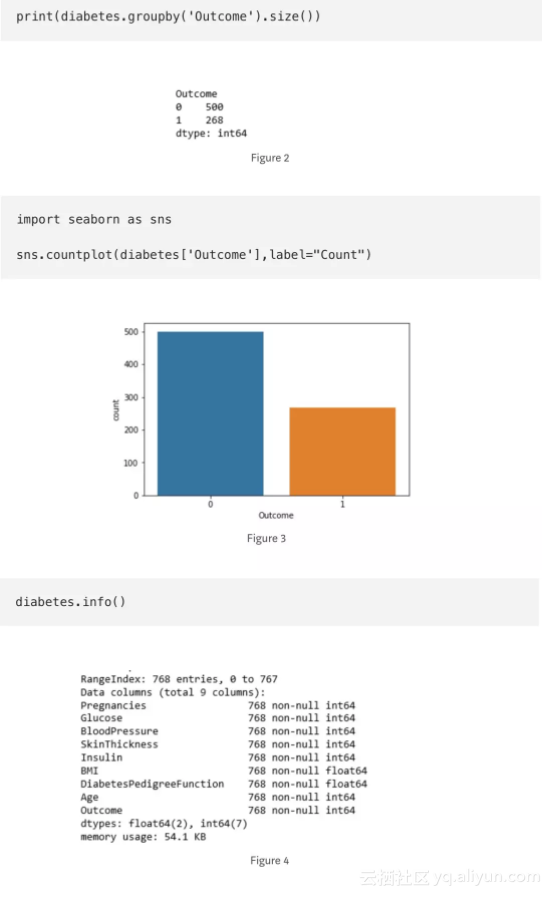
“结果”是我们将要预测的特征,0意味着未患糖尿病,1意味着患有糖尿病。在768个数据点中,500个被标记为0,268个标记为1。
https://yqfile.alicdn.com/5e4b68850f0f3f3381e76c3b7de14cfd09242445.png
{kind=link}
KNN算法
k-NN算法几乎可以说是机器学习中最简单的算法。建立模型只需存储训练数据集。而为了对新的数据点做出预测,该算法会在训练数据集中找到与其相距最近的数据点——也就是它的“近邻点”。
首先,让我们研究一下是否能够确认模型的复杂度和精确度之间的关系:
https://yqfile.alicdn.com/2c2cbfd821f1d4e890c16e6e58f4d3b27fb7482c.png
{kind=link}
上图展示了训练集和测试集在模型预测准确度(y轴)和近邻点个数设置(x轴)之间的关系。如果我们仅选择一个近邻点,那么训练集的预测是绝对正确的。但是当更多的近邻点被选入作为参考时,训练集的准确度会下降,这表明了使用单一近邻会导致模型太过复杂。这里的最好方案可以从图中看出是选择9个近邻点。
图中建议我们应该选择n_neighbors=9,下面给出:
https://yqfile.alicdn.com/2684defddc0b8618303fb68da7f46cb12a333c17.png
{kind=link}
K-NN分类的准确度在训练集中为:0.7
K-NN分类的准确度在测试集中为:0.7
逻辑回归
逻辑回归是最常见的分类算法之一。
https://yqfile.alicdn.com/ec79abe7126d0d1c5d565db72d5fd55a57533c77.png
{kind=link}
训练集准确度:0.781
测试集准确度:0.771
正则化参数C=1(默认值)的模型在训练集上准确度为78%,在测试集上准确度为77%。
https://yqfile.alicdn.com/154e2a59eaeb7f4354e57578677112cbcb7a04ba.png
{kind=link}
训练集准确度:0.785
测试集准确度:0.766
而将正则化参数C设置为100时,模型在训练集上准确度稍有提高但测试集上准确度略降,说明较少正则化和更复杂的模型并不一定会比默认参数模型的预测效果更好。
因此,我们选择默认值C=1。
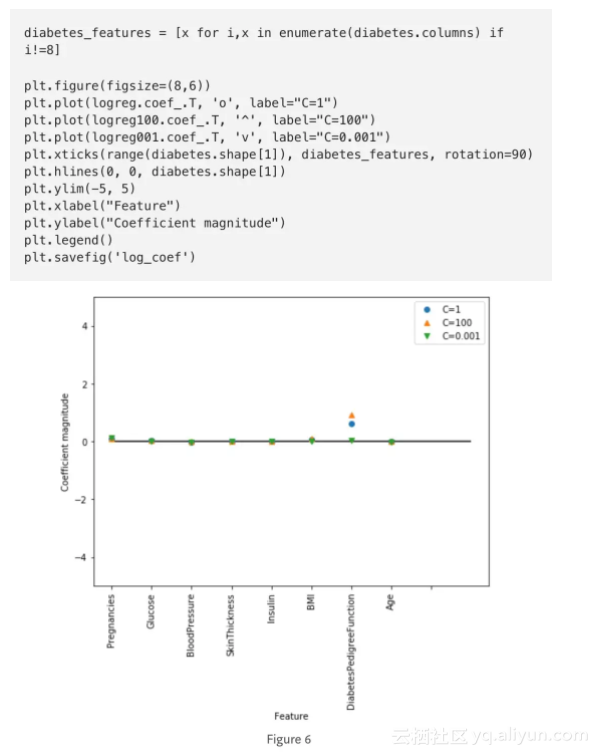
让我们用可视化的方式来看一下用三种不同正则化参数C所得模型的系数。
更强的正则化(C =
0.001)会使系数越来越接近于零。仔细地看图,我们还能发现特征“DiabetesPedigreeFunction
https://yqfile.alicdn.com/6c8af43ffa8a133176404df52c6d8dcef4601e0c.png
{kind=link}
决策树
https://yqfile.alicdn.com/ce7d8c965a4f531b666edf32940fa898f083f064.png
{kind=link}
训练集准确度:1.000
测试集准确度:0.714
训练集的准确度可以高达100%,而测试集的准确度相对就差了很多。这表明决策树是过度拟合的,不能对新数据产生好的效果。因此,我们需要对树进行预剪枝。
我们设置max_depth=3,限制树的深度以减少过拟合。这会使训练集的准确度降低,但测试集准确度提高。
https://yqfile.alicdn.com/b11d27afb23c55fca87c1bdb1de46c0348586474.png
{kind=link}
训练集准确度:0.773
测试集准确度:0.740
决策树中特征重要度
决策树中的特征重要度是用来衡量每个特征对于预测结果的重要性的。对每个特征有一个从0到1的打分,0表示“一点也没用”,1表示“完美预测”。各特征的重要度加和一定是为1的。
https://yqfile.alicdn.com/7150b5eb1e4c37dc922cb77e4b99bf4feb5a8032.png
{kind=link}
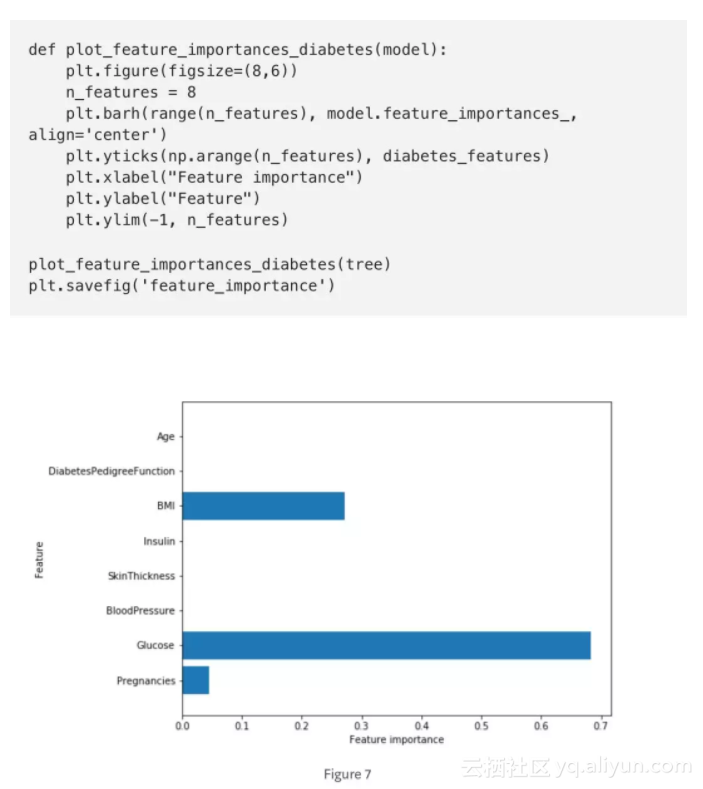
特征重要度:
[ 0.04554275 0.6830362 0. 0. 0. 0.27142106 0. 0. ]
然后我们能可视化特征重要度:
https://yqfile.alicdn.com/536e6ef5e87d108164c80d64514dcea0a1a0bcdc.png
{kind=link}
特征“血糖”是目前最重要的特征。
随机森林
让我们在糖尿病数据集中应用一个由100棵树组成的随机森林:
训练集准确度:1.000
测试集准确度:0.786
没有更改任何参数的随机森林有78.6%的准确度,比逻辑回归和单一决策树的预测效果更好。然而,我们还是可以调整max_features设置,看看效果是否能够提高。
https://yqfile.alicdn.com/d079b93027a27615891a738fcdc99a491c8c1d56.png
{kind=link}
训练集准确度:0.800
测试集准确度:0.755
结果并没有提高,这表明默认参数的随机森林在这里效果很好。
https://yqfile.alicdn.com/42f7fd45f5de311e067913a81dd5edd6dbe744f2.png
{kind=link}
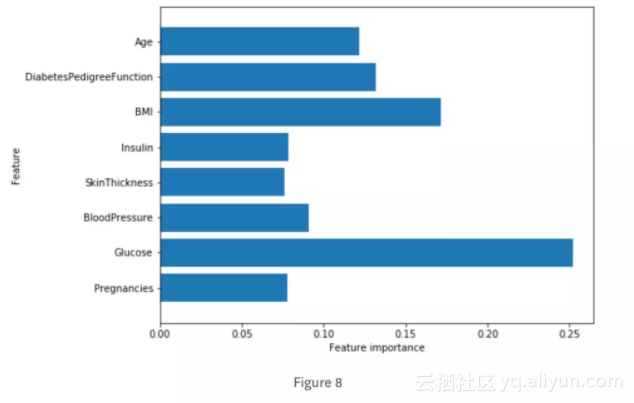
随机森林的特征重要度:
https://yqfile.alicdn.com/398f9b54417324a9072979179f7b16a918e77451.png
{kind=link}
与单一决策树相似,随机森林的结果仍然显示特征“血糖”的重要度最高,但是它也同样显示“BMI(身体质量指数)”在整体中是第二重要的信息特征。随机森林的随机性促使算法考虑了更多可能的解释,这就导致随机森林捕获的数据比单一树要大得多。
梯度提升
https://yqfile.alicdn.com/b8ebbad6e384fa9dcb51e3727151cdc21a76ca8d.png
{kind=link}
训练集准确度:0.917
测试集准确度:0.792
我们可能是过拟合了。为了降低这种过拟合,我们可以通过限制最大深度或降低学习速率来进行更强的修剪:
https://yqfile.alicdn.com/47dc18aa5e20cc351b4604695d69029c7812f943.png
{kind=link}
训练集准确度:0.804
测试集准确度:0.781
https://yqfile.alicdn.com/41ae6a9e6440b62c24377d291ba14a7d21f0e81b.png
{kind=link}
训练集准确度:0.802
测试集准确度:0.776
如我们所期望的,两种降低模型复杂度的方法都降低了训练集的准确度。可是测试集的泛化性能并没有提高。
尽管我们对这个模型的结果不是很满意,但我们还是希望通过特征重要度的可视化来对模型做更进一步的了解。
https://yqfile.alicdn.com/7954a168e11cd1b27103c1a4dc2426b7cada0d62.png
{kind=link}
我们可以看到,梯度提升树的特征重要度与随机森林的特征重要度有点类似,同时它给这个模型的所有特征赋了重要度值。
支持向量机
https://yqfile.alicdn.com/55364d6d9d3466155c0e228f2867a65b4648557c.png
{kind=link}
训练集准确度:1.00
测试集准确度:0.65
这个模型过拟合比较明显,虽然在训练集中有一个完美的表现,但是在测试集中仅仅有65%的准确度。
SVM要求所有的特征要在相似的度量范围内变化。我们需要重新调整各特征值尺度使其基本上在同一量表上。
https://yqfile.alicdn.com/4027fa715871726c96c14514f5cb7c04eee9582c.png
{kind=link}
训练集准确度:0.77
测试集准确度:0.77
数据的度量标准化后效果大不同!现在我们的模型在训练集和测试集的结果非常相似,这其实是有一点过低拟合的,但总体而言还是更接近100%准确度的。这样来看,我们还可以试着提高C值或者gamma值来配适更复杂的模型。
https://yqfile.alicdn.com/a1df0a8b398e121ad41ced431fc1375330b221d9.png
{kind=link}
训练集准确度:0.790
测试集准确度:0.7979
提高了C值后,模型效果确实有一定提升,测试集准确度提至79.7%。
深度学习
https://yqfile.alicdn.com/d14876d1bac9fa6eec84d60a8c6a34bc11949243.png
{kind=link}
训练集准确度:0.71
测试集准确度:0.67
多层神经网络(MLP)的预测准确度并不如其他模型表现的好,这可能是数据的尺度不同造成的。深度学习算法同样也希望所有输入的特征在同一尺度范围内变化。理想情况下,是均值为0,方差为1。所以,我们必须重新标准化我们的数据,以便能够满足这些需求。
https://yqfile.alicdn.com/376399f9c43ab29e5cbfa63552fde47e9b14f8c8.png
{kind=link}
训练集准确度“0.823
测试集准确度:0.802
让我们增加迭代次数:
https://yqfile.alicdn.com/e4a558681348b97aa510a4188b5d1ae6d028f44b.png
{kind=link}
训练集准确度:0.877
测试集准确度:0.755
增加迭代次数仅仅提升了训练集的性能,而对测试集没有效果。
让我们调高alpha参数并且加强权重的正则化。
https://yqfile.alicdn.com/dc6c49511f04563a934a8f22978e761ab068859a.png
{kind=link}
训练集准确度:0.795
测试集准确度:0.792
这个结果是好的,但我们无法更进一步提升测试集准确度。
因此,到目前为止我们最好的模型是在数据标准化后的默认参数深度学习模型。
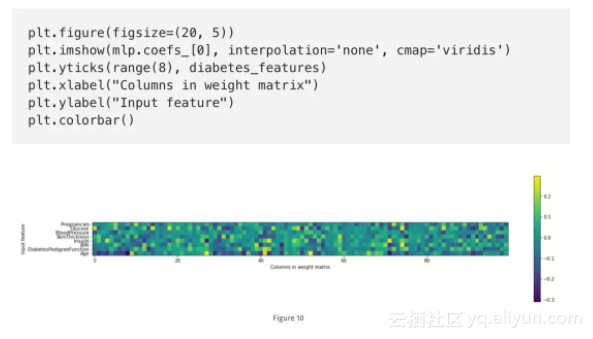
最后,我们绘制了一个在糖尿病数据集上学习的神经网络的第一层权重热图。
https://yqfile.alicdn.com/b6a09e066fe79af63fddd49906eb49c348dd6ca3.png
{kind=link}
从这个热度图中,快速指出哪个或哪些特征的权重较高或较低是不容易的。
设置正确的参数非常重要
本文我们练习了很多种不同的机器学习模型来进行分类和回归,了解了它们的优缺点是什么,以及如何控制其模型复杂度。我们同样看到,对于许多算法来说,设置正确的参数对于性能良好是非常重要的。
我们是应该要知道如何应用、调整和分析以上练习的模型的。现在该轮到你了!试着用这些算法中的任意一种在scikit-learn包中内置的数据集或任何你自己的数据集上去练习吧!享受机器学习吧!
![]() 喜欢
喜欢
0
![]() 赠金笔
赠金笔