 加载中…
加载中…2019CSP-s复赛DAY1
| 分类: 试题解 |
2019CSP day1t1 格雷码 P5657
题目描述
通常,人们习惯将所有 n位二进制串按照字典序排列,例如所有 2 位二进制串按字典序从小到大排列为:00,01,11,10。
格雷码(GrayCode)是一种特殊的 n位二进制串排列法,它要求相邻的两个二进制串间恰好有一位不同,特别地,第一个串与最后一个串也算作相邻。
所有 2位二进制串按格雷码排列的一个例子为:00,01,11,10。
n位格雷码不止一种,下面给出其中一种格雷码的生成算法:
1位格雷码由两个 1 位二进制串组成,顺序为:0,1。
n+1位格雷码的前 2^n 个二进制串,可以由依此算法生成的 n 位格雷码(总共 2^n 个 n 位二进制串)按顺序排列,再在每个串前加一个前缀 0构成。
n+1位格雷码的后 2^n 个二进制串,可以由依此算法生成的 n 位格雷码(总共 2^n 个 n 位二进制串)按逆序排列,再在每个串前加一个前缀 1构成。
综上,n+1位格雷码,由 n 位格雷码的 2^n个二进制串按顺序排列再加前缀 0,和按逆序排列再加前缀 1 构成,共 2^(n+1) 个二进制串。另外,对于 n 位格雷码中的 2^n个 二进制串,我们按上述算法得到的排列顺序将它们从 0~2^n-1编号。
按该算法,2位格雷码可以这样推出:
已知 1位格雷码为 0,1。
前两个格雷码为00,01。后两个格雷码为 11,10。合并得到 00,01,11,10,编号依次为 0~3。
同理,3位格雷码可以这样推出:
已知 2位格雷码为:00,01,11,10。
前四个格雷码为:000,001,011,010。后四个格雷码为:110,111,101,100。合并得到:000,001,011,010,110,111,101,100,编号依次为 0~7。
现在给出 n,k,请你求出按上述算法生成的 n 位格雷码中的 k号二进制串。
输入格式
仅一行两个整数 n,k,意义见题目描述。
输出格式
仅一行一个 n位二进制串表示答案。
输入 #1
2 3
输出 #1
10
输入 #2
3 5
输出 #2
111
输入 #3
44 1145141919810
输出 #3
00011000111111010000001001001000000001100011
说明/提示
【样例 1解释】
2位格雷码为:00,01,11,10,编号从 0~3,因此 3 号串是 10。
【样例 2解释】
3位格雷码为:000,001,011,010,110,111,101,100,编号从 0~7,因此 5 号串是 111。
【数据范围】
对于 50%的数据:n≤10
对于 80%的数据:k≤5×10^6
对于 95%的数据:k≤2^63-1
对于 100%的数据:1≤n≤64, 0≤k < 2n
简单模拟
#include "bits/stdc++.h"
#define ull unsigned long long
using namespace std;
string fn(ull n,ull k){
ull
mid=1ull<<(n-1);
if (n==0)
return "";
if (k <
mid) return "0"+fn(n-1,k);
else return
"1"+fn(n-1,mid-1-(k-mid));
}
int main(){
ull n;ull
k;
cin>>n>>k;
cout<<fn(n,k);
}
2019CSP day1t2 括号树 P5658
2019CSP day1t2 格雷码 P5658/ybt1987
本题中合法括号串的定义如下:
1. () 是合法括号串。
2. 如果 A 是合法括号串,则 (A) 是合法括号串。
3. 如果 A,B 是合法括号串,则 AB 是合法括号串。
本题中子串与不同的子串的定义如下:
1. 字符串 S 的子串是 S 中连 续. 的任意个字符组成的字符串。S 的子串可用起始位置 l 与终止位置 r 来表示,记为 S (l,r)(1 ≤ l ≤ r ≤ |S |,|S | 表示 S 的长度)。
2. S 的两个子串视作不同当且仅当它们在 S 中的位置不同,即 l 不同或 r 不同。
一个大小为 n 的树包含 n 个结点和 n ? 1 条边,每条边连接两个结点,且任意两个结点间有且仅有一条简单路径互相可达。
小 Q 是一个充满好奇心的小朋友,有一天他在上学的路上碰见了一个大小为 n 的树,树上结点从 1 ~ n 编号,1 号结点为树的根。除 1 号结点外,每个结点有一个父亲结点,u(2 ≤ u ≤ n)号结点的父亲为 fu(1≤fu < u)号结点。
小 Q 发现这个树的每个结点上恰有一个括号,可能是’(’ 或’)’。小 Q 定义 si为:将根结点到 i 号结点的简单路径上的括号,按结点经过顺序依次排列组成的字符串。显然 si是个括号串,但不一定是合法括号串,因此现在小 Q 想对所有的 i(1≤i≤n)求出,si中有多少个互不相同的子串是合法括号串。
这个问题难倒了小 Q,他只好向你求助。设 si共有 ki 个不同子串是合法括号串,你只需要告诉小 Q 所有 i×ki的异或和,即:
(1×k1)xor(2×k2)xor(3×k3)xor……xor (n×kn)
其中 xor是位异或运算。
【输入】
第一行一个整数 n,表示树的大小。
第二行一个长为 n的由’(’ 与’)’ 组成的括号串,第 i 个括号表示 i号结点上的括号。
第三行包含 n-1个整数,第 i(1≤i < n)个整数表示 i+1 号结点的父亲编号 f(i+1)。
【输出】
仅一行一个整数表示答案。
【输入样例】
5
(()()
1 1 2 2
【输出样例】
6
【提示】
【样例 1 解释】
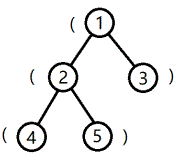
树的形态如下图:
http://ybt.ssoier.cn:8088/pic/1987.gif
【样例 1 解释】
树的形态如下图:
将根到 1 号结点的简单路径上的括号,按经过顺序排列所组成的字符串为 (,子串是合法括号串的个数为 0。
将根到 2 号结点的简单路径上的括号,按经过顺序排列所组成的字符串为 ((,子串是合法括号串的个数为 0。
将根到 3 号结点的简单路径上的括号,按经过顺序排列所组成的字符串为 (),子串是合法括号串的个数为 1。
将根到 4 号结点的简单路径上的括号,按经过顺序排列所组成的字符串为 (((,子串是合法括号串的个数为 0。
将根到 5 号结点的简单路径上的括号,按经过顺序排列所组成的字符串为 ((),子串是合法括号串的个数为 1。
【数据范围】
测试点编号 n
≤ 特殊性质
1~2
8
fi=i-1
3~4 200
5~7
2000
8~10 无
11~14
10^5
fi=i-1
15~16 无
17~20
5×10^5
#include "bits/stdc++.h"
using namespace std;
typedef long long ll;
const int N=5e5+5;
int n,tot,head[N],a[N],fa[N],re[N];
ll ans,cnt[N];
char temp[N];
struct Edge
{
int
to,next;
void add(int
x, int y) { to=y,next=head[x],head[x]=tot; }
} e[N<<1];
void dfs(int x, int f)
{
cnt[x]+=cnt[f],fa[x]=f;//cnt记录子串数
if
(a[x]==1)
{//如果是右括号
while (a[f]!=-1 && re[f]!=-1)
f=fa[re[f]];//向根,找第一个未匹配弧
if (f==0 || a[f]==1) re[x]=-1;//如果是根,或者已经匹配
else{
re[x]=f;//匹配x的左括弧
cnt[x]+=cnt[fa[f]]-cnt[fa[fa[f]]]+1;
}
}else
re[x]=-1;//copy from a[x] as primitive value,记录已匹配子串
for (int
i=head[x];i;i=e[i].next)
{
int v=e[i].to;
dfs(v,x);
}
}
int main()
{
cin>>n;
scanf("%s",temp);
for (int
i=1;i<=n;i++)
a[i]=(temp[i-1]=='('?-1:1);
for (int
i=2,f;i<=n;i++) cin>>f,e[++tot].add(f,i);
re[0]=-1;
dfs(1,0);
for (ll
i=1;i<=n;i++) ans^=(cnt[i]*i);
printf("%lld\n",ans);
return
0;
}
2019CSP day1t3 树的计数 P5659
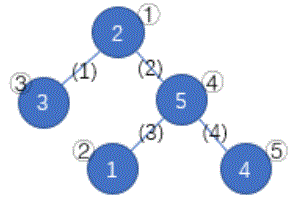
给定一个大小为 n 的树,它共有 n 个结点与 n-1 条边,结点从 1~n 编号。初始时每个结点上都有一个 1~n 的数字,且每个 1~n的数字都只在恰好一个结点上出现。接下来你需要进行恰好n-1次删边操作,每次操作你需要选一条未被删去的边,此时这条边所连接的两个结点上的数字将会交换,然后这条边将被删去。n-1次操作过后,所有的边都将被删去。此时,按数字从小到大的顺序,将数字1~n 所在的结点编号依次排列,就得到一个结点编号的排列 Pi。现在请你求出,在最优操作方案下能得到的字典序最小的 Pi。
http://ybt.ssoier.cn:8088/pic/1988a.gif
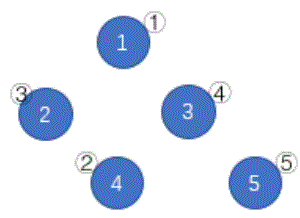
如上图,蓝圈中的数字 1~5
一开始分别在结点 、 、 、 、 。按照
(1)(4)(3)(2)的顺序删去所有边,树变为下图。按数字顺序得到的结点编号排列为
,该排列是所有可能的结果中字典序最小的。
http://ybt.ssoier.cn:8088/pic/1988b.gif
【输入】
本题输入包含多组测试数据。
第一行一个正整数 T,表示数据组数。
对于每组测试数据:
第一行一个整数 n,表示树的大小。
第二行 n 个整数,第 i(1 ≤ i ≤ n)个整数表示数字 i 初始时所在的结点编号。
接下来 n - 1 行每行两个整数 x, y,表示一条连接 x 号结点与 y 号结点的边。
【输出】
对于每组测试数据,输出一行共 n 个用空格隔开的整数,表示最优操作方案下所能得到的字典序最小的 Pi。
【输入样例】
4
5
2 1 3 5 4
1 3
1 4
2 4
4 5
5
3 4 2 1 5
1 2
2 3
3 4
4 5
5
1 2 5 3 4
1 2
1 3
1 4
1 5
10
1 2 3 4 5 7 8 9 10 6
1 2
1 3
1 4
1 5
5 6
6 7
7 8
8 9
9 10
【输出样例】
1 3 4 2 5
1 3 5 2 4
2 3 1 4 5
2 3 4 5 6 1 7 8 9 10
【提示】
【数据范围】
测试点编号 n
≤ 特殊性质
1 ~ 2
10 无
3 ~ 4
160
树的形态是一条链
5 ~ 7
2000
8 ~ 9
160 存在度数为 n ?
1 的结点
10 ~ 12
2000
13 ~ 16
160 存在度数为 n ?
1 的结点
17 ~ 20
2000
对于所有测试点:1≤T≤10,保证给出的是一个树。
#define maxn
2005
using
namespace std;
struct
node
{
int fa[maxn],nex[maxn],notrt[maxn];//全部边的编号都除以二
题目描述
通常,人们习惯将所有 n位二进制串按照字典序排列,例如所有 2 位二进制串按字典序从小到大排列为:00,01,11,10。
格雷码(GrayCode)是一种特殊的 n位二进制串排列法,它要求相邻的两个二进制串间恰好有一位不同,特别地,第一个串与最后一个串也算作相邻。
所有 2位二进制串按格雷码排列的一个例子为:00,01,11,10。
n位格雷码不止一种,下面给出其中一种格雷码的生成算法:
1位格雷码由两个 1 位二进制串组成,顺序为:0,1。
n+1位格雷码的前 2^n 个二进制串,可以由依此算法生成的 n 位格雷码(总共 2^n 个 n 位二进制串)按顺序排列,再在每个串前加一个前缀 0构成。
n+1位格雷码的后 2^n 个二进制串,可以由依此算法生成的 n 位格雷码(总共 2^n 个 n 位二进制串)按逆序排列,再在每个串前加一个前缀 1构成。
综上,n+1位格雷码,由 n 位格雷码的 2^n个二进制串按顺序排列再加前缀 0,和按逆序排列再加前缀 1 构成,共 2^(n+1) 个二进制串。另外,对于 n 位格雷码中的 2^n个 二进制串,我们按上述算法得到的排列顺序将它们从 0~2^n-1编号。
按该算法,2位格雷码可以这样推出:
已知 1位格雷码为 0,1。
前两个格雷码为00,01。后两个格雷码为 11,10。合并得到 00,01,11,10,编号依次为 0~3。
同理,3位格雷码可以这样推出:
已知 2位格雷码为:00,01,11,10。
前四个格雷码为:000,001,011,010。后四个格雷码为:110,111,101,100。合并得到:000,001,011,010,110,111,101,100,编号依次为 0~7。
现在给出 n,k,请你求出按上述算法生成的 n 位格雷码中的 k号二进制串。
输入格式
仅一行两个整数 n,k,意义见题目描述。
输出格式
仅一行一个 n位二进制串表示答案。
输入 #1
2 3
输出 #1
10
输入 #2
3 5
输出 #2
111
输入 #3
44 1145141919810
输出 #3
000110001111110100000010
说明/提示
【样例 1解释】
2位格雷码为:00,01,11,10,编号从 0~3,因此 3 号串是 10。
【样例 2解释】
3位格雷码为:000,001,011,010,110,111,101,100,编号从 0~7,因此 5 号串是 111。
【数据范围】
对于 50%的数据:n≤10
对于 80%的数据:k≤5×10^6
对于 95%的数据:k≤2^63-1
对于 100%的数据:1≤n≤64, 0≤k < 2n
简单模拟
#include "bits/stdc++.h"
#define ull unsigned long long
using namespace std;
string fn(ull n,ull k){
}
int main(){
}
2019CSP day1t2 括号树 P5658
2019CSP day1t2 格雷码
本题中合法括号串的定义如下:
1. () 是合法括号串。
2. 如果 A 是合法括号串,则 (A) 是合法括号串。
3. 如果 A,B 是合法括号串,则 AB 是合法括号串。
本题中子串与不同的子串的定义如下:
1. 字符串 S 的子串是 S 中连 续. 的任意个字符组成的字符串。S 的子串可用起始位置 l 与终止位置 r 来表示,记为 S (l,r)(1 ≤ l ≤ r ≤ |S |,|S | 表示 S 的长度)。
2. S 的两个子串视作不同当且仅当它们在 S 中的位置不同,即 l 不同或 r 不同。
一个大小为 n 的树包含 n 个结点和 n ? 1 条边,每条边连接两个结点,且任意两个结点间有且仅有一条简单路径互相可达。
小 Q 是一个充满好奇心的小朋友,有一天他在上学的路上碰见了一个大小为 n 的树,树上结点从 1 ~ n 编号,1 号结点为树的根。除 1 号结点外,每个结点有一个父亲结点,u(2 ≤ u ≤ n)号结点的父亲为 fu(1≤fu < u)号结点。
小 Q 发现这个树的每个结点上恰有一个括号,可能是’(’ 或’)’。小 Q 定义 si为:将根结点到 i 号结点的简单路径上的括号,按结点经过顺序依次排列组成的字符串。显然 si是个括号串,但不一定是合法括号串,因此现在小 Q 想对所有的 i(1≤i≤n)求出,si中有多少个互不相同的子串是合法括号串。
这个问题难倒了小 Q,他只好向你求助。设 si共有 ki 个不同子串是合法括号串,你只需要告诉小 Q 所有 i×ki的异或和,即:
(1×k1)xor(2×k2)xor(3×k3)xor……xor (n×kn)
其中 xor是位异或运算。
【输入】
第一行一个整数 n,表示树的大小。
第二行一个长为 n的由’(’ 与’)’ 组成的括号串,第 i 个括号表示 i号结点上的括号。
第三行包含 n-1个整数,第 i(1≤i < n)个整数表示 i+1 号结点的父亲编号 f(i+1)。
【输出】
仅一行一个整数表示答案。
【输入样例】
5
(()()
1 1 2 2
【输出样例】
6
【提示】
【样例 1 解释】
树的形态如下图:
http://ybt.ssoier.cn:8088/pic/1987.gif
{kind=link}
【样例 1 解释】
树的形态如下图:
将根到 1 号结点的简单路径上的括号,按经过顺序排列所组成的字符串为 (,子串是合法括号串的个数为 0。
将根到 2 号结点的简单路径上的括号,按经过顺序排列所组成的字符串为 ((,子串是合法括号串的个数为 0。
将根到 3 号结点的简单路径上的括号,按经过顺序排列所组成的字符串为 (),子串是合法括号串的个数为 1。
将根到 4 号结点的简单路径上的括号,按经过顺序排列所组成的字符串为 (((,子串是合法括号串的个数为 0。
将根到 5 号结点的简单路径上的括号,按经过顺序排列所组成的字符串为 ((),子串是合法括号串的个数为 1。
【数据范围】
测试点编号
1~2
3~4
5~7
8~10
11~14
15~16
17~20
#include "bits/stdc++.h"
using namespace std;
typedef long long ll;
const int N=5e5+5;
int n,tot,head[N],a[N],fa[N],re[N];
ll ans,cnt[N];
char temp[N];
struct Edge
{
} e[N<<1];
void dfs(int x, int f)
{
}
int main()
{
}
2019CSP day1t3 树的计数
给定一个大小为 n 的树,它共有 n 个结点与 n-1 条边,结点从 1~n 编号。初始时每个结点上都有一个 1~n 的数字,且每个 1~n的数字都只在恰好一个结点上出现。接下来你需要进行恰好n-1次删边操作,每次操作你需要选一条未被删去的边,此时这条边所连接的两个结点上的数字将会交换,然后这条边将被删去。n-1次操作过后,所有的边都将被删去。此时,按数字从小到大的顺序,将数字1~n 所在的结点编号依次排列,就得到一个结点编号的排列 Pi。现在请你求出,在最优操作方案下能得到的字典序最小的 Pi。
http://ybt.ssoier.cn:8088/pic/1988a.gif
{kind=link}
如上图,蓝圈中的数字 1~5
一开始分别在结点 、 、
http://ybt.ssoier.cn:8088/pic/1988b.gif
{kind=link}
【输入】
本题输入包含多组测试数据。
第一行一个正整数 T,表示数据组数。
对于每组测试数据:
第一行一个整数 n,表示树的大小。
第二行 n 个整数,第 i(1 ≤ i ≤ n)个整数表示数字 i 初始时所在的结点编号。
接下来 n - 1 行每行两个整数 x, y,表示一条连接 x 号结点与 y 号结点的边。
【输出】
对于每组测试数据,输出一行共 n 个用空格隔开的整数,表示最优操作方案下所能得到的字典序最小的 Pi。
【输入样例】
4
5
2 1 3 5 4
1 3
1 4
2 4
4 5
5
3 4 2 1 5
1 2
2 3
3 4
4 5
5
1 2 5 3 4
1 2
1 3
1 4
1 5
10
1 2 3 4 5 7 8 9 10 6
1 2
1 3
1 4
1 5
5 6
6 7
7 8
8 9
9 10
【输出样例】
1 3 4 2 5
1 3 5 2 4
2 3 1 4 5
2 3 4 5 6 1 7 8 9 10
【提示】
【数据范围】
测试点编号
1 ~ 2
3 ~ 4
5 ~ 7
8 ~ 9
10 ~ 12
13 ~ 16
17 ~ 20
对于所有测试点:1≤T≤10,保证给出的是一个树。