 加载中…
加载中…集成学习之Adaboost算法损失函数优化
| 分类: MachineLearning |
1、回顾boosting算法的基本原理:
1)学习误差率e
2) 弱学习器权重系数α"
role="presentation">
{kind=link}
3)样本权重D
4) 结合策略
2、Adaboost算法的基本思路:
我们这里讲解Adaboost是如何解决上一节这4个问题的。
假设我们的训练集样本是
{kind=link}
训练集的在第k个弱学习器的输出权重为
{kind=link}
首先我们看看Adaboost的分类问题。
分类问题的误差率很好理解和计算。由于多元分类是二元分类的推广,这里假设我们是二元分类问题,输出为{-1,1},则第k个弱分类器Gk(x)"
role="presentation">
{kind=link}
接着我们看弱学习器权重系数,对于二元分类问题,第k个弱分类器Gk(x)"
role="presentation">
 http://mathjax.cnblogs.com/2_6_1/fonts/HTML-CSS/TeX/png/Math/Italic/100/006B.png?rev=2.6.1
http://mathjax.cnblogs.com/2_6_1/fonts/HTML-CSS/TeX/png/Math/Italic/100/006B.png?rev=2.6.1 {kind=link}
为什么这样计算弱学习器权重系数?从上式可以看出,如果分类误差率ek"
role="presentation">
第三个问题,更新更新样本权重D。假设第k个弱分类器的样本集权重系数为D(k)=(wk1,wk2,...wkm)"
role="presentation">
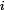{kind=link} http://mathjax.cnblogs.com/2_6_1/fonts/HTML-CSS/TeX/png/Math/Italic/141/03B1.png?rev=2.6.1
http://mathjax.cnblogs.com/2_6_1/fonts/HTML-CSS/TeX/png/Math/Italic/141/03B1.png?rev=2.6.1 这里Zk" role="presentation">
http://mathjax.cnblogs.com/2_6_1/fonts/HTML-CSS/TeX/png/Math/Italic/141/03B1.png?rev=2.6.1 从wk+1,i" role="presentation">
{kind=link}
最后一个问题是集合策略。Adaboost分类采用的是加权平均法,最终的强分类器为
上一节我们讲到了分类Adaboost的弱学习器权重系数公式和样本权重更新公式。但是没有解释选择这个公式的原因。其实它可以从Adaboost的损失函数推导出来。
从另一个角度讲, Adaboost是模型为加法模型,学习算法为前向分步学习算法,损失函数为指数函数的分类问题。
模型为加法模型好理解,我们的最终的强分类器是若干个弱分类器加权平均而得到的。
前向分步学习算法也好理解,我们的算法是通过一轮轮的弱学习器学习,利用前一个弱学习器的结果来更新后一个弱学习器的训练集权重。也就是说,第k-1轮的强学习器为fk−1(x)=k−1∑i=1αiGi(x)
而第k轮的强学习器为fk(x)=k∑i=1αiGi(x)
上两式一比较可以得到fk(x)=fk−1(x)+αkGk(x)
可见强学习器的确是通过前向分步学习算法一步步而得到的。
Adaboost损失函数为指数函数,即定义损失函数为argmin⏟α,Gm∑i=1exp(−yifk(x))
利用前向分步学习算法的关系可以得到损失函数为(αk,Gk(x))=argmin⏟α,Gm∑i=1exp[(−yi)(fk−1(x)+αG(x))]
令w′ki=exp(−yifk−1(x)), 它的值不依赖于α,G,因此与最小化无关,仅仅依赖于fk−1(x),随着每一轮迭代而改变。
将这个式子带入损失函数,损失函数转化为(αk,Gk(x))=argmin⏟α,Gm∑i=1w′kiexp[−yiαG(x)]
首先,我们求Gk(x).,可以得到Gk(x)=argmin⏟Gm∑i=1w′kiI(yi≠G(xi))
将Gk(x)带入损失函数,并对α求导,使其等于0,则就得到了αk=12log1−ekek
其中,ek即为我们前面的分类误差率。ek=m∑i=1w′kiI(yi≠G(xi))m∑i=1w′ki=m∑i=1wkiI(yi≠G(xi))
最后看样本权重的更新。利用fk(x)=fk−1(x)+αkGk(x)和w′ki=exp(−yifk−1(x)),即可得:w′k+1,i=w′kiexp[−yiαkGk(x)]
这样就得到了我们第二节的样本权重更新公式。
![]() 喜欢
喜欢
0
![]() 赠金笔
赠金笔