 加载中…
加载中…5.31 GROUP BY子句 & LIMIT子句 & UNION语句 & HANDLER语句
标签:
it |
分类: MySql |
GROUP BY子句
GROUP BY子句主要用于根据字段对行分组。例如,根据学生所学的专业对XS表中的所有行分组,结果是每个专业的学生成为一组。GROUP BY子句的语法格式如下:
GROUP BY {col_name | expr | position} [ASC| DESC], ... [WITH ROLLUP]
说明:
GROUP BY子句后通常包含列名或表达式。MySQL对GROUP BY子句进行了扩展,可以在列的后面指定ASC(升序)或DESC(降序)。GROUP BY可以根据一个或多个列进行分组,也可以根据表达式进行分组,经常和聚合函数一起使用。
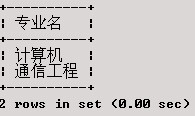
将XSCJ数据库中各专业名输出。
SELECT 专业名
执行结果为:
http://my.csdn.net/uploads/201205/31/1338466883_1231.jpgGROUP
{kind=link}
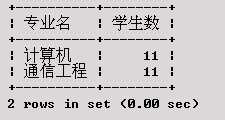
求XSCJ数据库中各专业的学生数。
SELECT 专业名,COUNT(*) AS '学生数'
执行结果为:
http://my.csdn.net/uploads/201205/31/1338466886_1229.jpgGROUP
{kind=link}
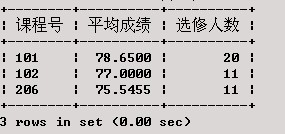
求被选修的各门课程的平均成绩和选修该课程的人数。
SELECT 课程号, AVG(成绩) AS '平均成绩' ,COUNT(学号) AS '选修人数'
执行结果为:
http://my.csdn.net/uploads/201205/31/1338466891_4698.jpgGROUP
{kind=link}
使用带ROLLUP操作符的GROUP BY子句: 指定在结果集内不仅包含由 GROUP BY 提供的正常行,还包含汇总行。
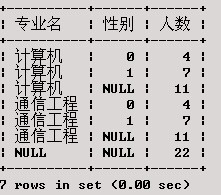
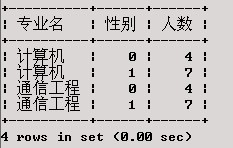
在XSCJ数据库上产生一个结果集,包括每个专业的男生人数、女生人数、总人数,以及学生总人数。
SELECT 专业名, 性别, COUNT(*) AS'人数'
执行结果为:
http://my.csdn.net/uploads/201205/31/1338466896_5185.jpgGROUP
{kind=link}
从上述执行结果可以看出,使用了ROLLUP操作符后,将对GROUPBY子句中所指定的各列产生汇总行,产生的规则是:按列的排列的逆序依次进行汇总。如本例根据专业名和性别将XS表分为4组,使用ROLLUP后,先对性别字段产生了汇总行(针对专业名相同的行),然后对专业名与性别均不同的值产生了汇总行。所产生的汇总行中对应具有不同列值的字段值将置为NULL。
可以将上述语句与不带ROLLUP操作符的GROUP BY子句的执行情况做一个比较:
SELECT 专业名, 性别, COUNT(*)AS '人数'
执行结果为:
{kind=link}
还可以将专业名与性别顺序交换一下看看执行情况。
带ROLLUP的GROUP BY子句可以与复杂的查询条件及连接查询一起使用。
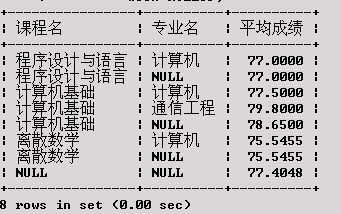
在XSCJ数据库上产生一个结果集,包括每门课程各专业的平均成绩、每门课程的总平均成绩和所有课程的总平均成绩。
SELECT 课程名, 专业名, AVG(成绩) AS '平均成绩'
执行结果为:
http://my.csdn.net/uploads/201205/31/1338466906_3058.jpgGROUP
{kind=link}
使用HAVING子句的目的与WHERE子句类似,不同的是WHERE子句是用来在FROM子句之后选择行,而HAVING子句用来在GROUP BY子句后选择行。例如,查找XSCJ数据库中平均成绩在85分以上的学生,就是在XS_KC表上按学号分组后筛选出符合平均成绩大于等于85的学生。
语法格式:
HAVING where_definition
其中,where_definition是选择条件,条件的定义和WHERE子句中的条件类似,不过HAVING子句中的条件可以包含聚合函数,而WHERE子句中则不可以。
SQL标准要求HAVING必须引用GROUP BY子句中的列或用于聚合函数中的列。不过,MySQL支持对此工作性质的扩展,并允许HAVING引用SELECT清单中的列和外部子查询中的列。
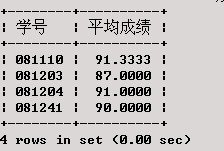
查找XSCJ数据库中平均成绩在85分以上的学生的学号和平均成绩。
SELECT 学号, AVG(成绩) AS '平均成绩'
执行结果:
{kind=link}
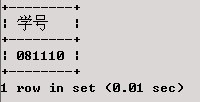
查找选修课程超过2门且成绩都在80分以上的学生的学号。
SELECT 学号
查询结果:
http://my.csdn.net/uploads/201205/31/1338466913_9063.jpgGROUP
{kind=link}
分析:本查询将XS_KC表中成绩大于80的记录按学号分组,对每组记录计数,选出记录数大于2的各组的学号值形成结果表。
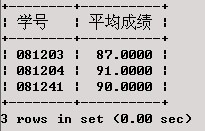
查找通信工程专业平均成绩在85分以上的学生的学号和平均成绩。
SELECT 学号,AVG(成绩) AS '平均成绩'
查询结果:
http://my.csdn.net/uploads/201205/31/1338466918_9528.jpgGROUP
{kind=link}
分析:先执行WHERE查询条件中的子查询,得到通信工程专业所有学生的学号集;然后对XS_KC中的每条记录,判断其学号字段值是否在前面所求得的学号集中。若否,则跳过该记录,继续处理下一条记录,若是,则加入WHERE的结果集。对XS_KC表筛选完后,按学号进行分组,再在各分组记录中选出平均成绩值大于等于85的记录,形成最后的结果集。
在一条SELECT语句中,如果不使用ORDER BY子句,结果中行的顺序是不可预料的。使用ORDER BY子句后可以保证结果中的行按一定顺序排列。
语法格式:
ORDER BY {col_name | expr | position} [ASC| DESC] , ...
说明:ORDER BY子句后可以是一个列、一个表达式或一个正整数。正整数表示按结果表中该位置上的列排序。例如,使用ORDER BY 3表示对SELECT的列清单上的第3列进行排序。
关键字ASC表示升序排列,DESC表示降序排列,系统默认值为ASC。
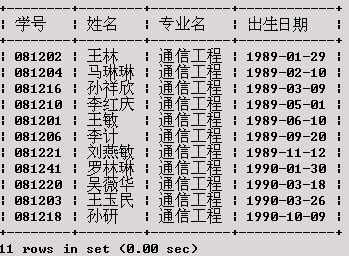
将通信工程专业的学生按出生日期先后排序。
SELECT 学号,姓名,专业名,出生日期
执行结果如下:
http://my.csdn.net/uploads/201205/31/1338466926_4385.jpgGROUP
{kind=link}
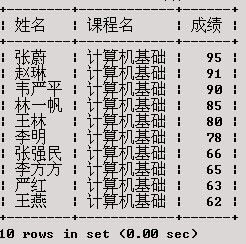
将计算机专业学生的“计算机基础”课程成绩按降序排列。
SELECT 姓名,课程名,成绩
执行结果如下:
http://my.csdn.net/uploads/201205/31/1338466933_2732.jpgGROUP
{kind=link}
ORDER BY子句中还可以包含子查询。
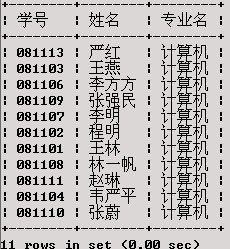
将计算机专业学生按其平均成绩排列。
SELECT
执行结果如下:
http://my.csdn.net/uploads/201205/31/1338466938_9633.jpgGROUP
{kind=link}
注意:当对空值排序时,ORDERBY子句将空值作为最小值对待,按升序排列的话将空值放在最上方,降序放在最下方。
LIMIT子句
LIMIT子句是SELECT语句的最后一个子句,主要用于限制被SELECT语句返回的行数。
语法格式:
LIMIT {[offset,] row_count | row_countOFFSET offset}
说明:
语法格式中的offset和row_count都必须是非负的整数常数,offset指定返回的第一行的偏移量,row_count是返回的行数。例如,“LIMIT 5”表示返回SELECT语句的结果集中最前面5行,而“LIMIT 3,5”则表示从第4行开始返回5行。值得注意的是初始行的偏移量为0而不是1。
查找XS表中学号最靠前的5位学生的信息。
SELECT 学号, 姓名, 专业名, 性别, 出生日期, 总学分
查询结果:
http://my.csdn.net/uploads/201205/31/1338466944_5826.jpgGROUP
{kind=link}
查找XS表中从第4位同学开始的5位学生的信息。
SELECT 学号, 姓名, 专业名, 性别, 出生日期, 总学分
查询结果:
{kind=link}
为了与PostgreSQL兼容,MySQL也支持LIMIT row_count OFFSET offset语法。所以将上面例子中的LIMIT子句换成“LIMIT 5 OFFSET 3”,结果一样。
UNION语句
使用UNION可以把来自许多SELECT语句的结果组合到一个结果集合中。
语法格式如下:
SELECT ...
UNION [ALL | DISTINCT]
SELECT ...
[UNION [ALL | DISTINCT]
SELECT ...]
说明:
SELECT语句为常规的选择语句,但是还必须遵守以下规则:
●
●
●
●
使用UNION的时候,在第一个SELECT语句中被使用的列名称被用于结果的列名称。MySQL自动从最终结果中去除重复行,所以附加的DISTINCT是多余的,但根据SQL标准,在语法上允许采用。要得到所有匹配的行,则可以指定关键字ALL。
查找学号为081101和学号为081210的两位同学的信息。
SELECT 学号, 姓名, 专业名, 性别, 出生日期, 总学分
查询结果:
{kind=link}
HANDLER语句
1.
可以使用HANDLEROPEN语句打开一个表。
语法格式为:
HANDLER tbl_name OPEN [ AS alias ]
说明:tbl_name是表名,可以使用AS子句给表定义一个别名。若打开表时使用别名,则在其他进一步访问表的语句也都要使用别名。
2.
HANDLER READ语句用于浏览一个已经打开的表的数据行。
语法格式为:
HANDLER tbl_name READ { FIRST | NEXT }
说明:
●
●
●
由于没有其他的声明,在读取一行数据的时候行的顺序是由MySQL决定的。如果要按某个顺序来显示,可以通过在HANDLER READ语句中指定索引来实现。
语法格式为:
HANDLER tbl_name READ index_name { = |>= |
<= | < }
(value1,value2,...)
HANDLER tbl_name READ index_name { FIRST |NEXT | PREV | LAST }
说明:
第一种方式是使用比较运算符为索引指定一个值,并从符合该条件的一行数据开始读取表。如果是多列索引,则值为多个值的组合,中间用逗号隔开。Index_name为索引名,value1、value2是为索引指定的值。
第二种方式是使用关键字读取行,FIRST表示第一行,NEXT表示下一行,PREV表示上一行,LAST表示最后一行。
有关索引的内容将在第5章中介绍,如有问题可参照第5章内容。
3.
行读取完后必须使用HANDLERCLOSE语句来关闭表。
语法格式为:
HANDLER tbl_name CLOSE
一行一行地浏览KC表中的满足要求的内容,要求第一行为学分大于4的第一行数据。
首先打开表:
USE XSCJ
HANDLER KC OPEN;
读取满足条件的第一行:
HANDLER KC READ FIRST
运行结果为:
{kind=link}
读取下一行:
HANDLER KC READ NEXT;
运行结果为:
{kind=link}
关闭该表:
HANDLER KC CLOSE;
![]() 喜欢
喜欢
0
![]() 赠金笔
赠金笔